Homework 1
This homework has 5 problems. The goal of the first homework is to ensure that you can access the compute resources on campus, compile MPI programs, understand the cost of communication to computation, use MPI_Send and MPI_Recv, and debug your program
Collaboration
You may discuss all aspects of the program with your classmates. However, you should never show any of your code to another student, and you should never copy anyone else's code without an explicit acknowledgment.
1) Ping Pong
In this problem we will investigate the relative cost of communication. A ping-pong program looks something like this:
/* Assume two processes */
if (my_rank == 0) {
start timer;
send message;
receive message;
stop timer;
print time;
} else /* my_rank == 1 */ {
receive message;
send message;
}
At a minimum you should take timings for messages: with lengths 0 bytes, 1024 bytes, 2048 bytes, 3072 bytes, ... , 131,072 bytes.
After taking your timings you should use least squares to fit a line to your data. The reciprocal of the slope is often called the bandwidth, and the intercept the latency.
Use MPI_WTime() to get the wall-clock time.
Since MPI_WTime() only has a precision of about .1ms one volley of messages may not be enough.
So implement something like this:
if (my_rank == 0) {
start timer;
for (i = 0; i < MESSAGE_COUNT; i++) {
send message;
receive message;
}
stop timer;
print Average message time = elapsed time/(2*MESSAGE_COUNT);
} else {
for (i = 0; i < MESSAGE_COUNT; i++) {
receive message;
send message;
}
}
Run this code on a single machine such as your laptop, and then on a cluster between two different machines.
Experiment a bit with this process.
Do the first 10-20 messages take longer than the later messages?
Was there much variation in the ping-pong times for messages of a fixed size? If so, can you or a suggestion about why this might be the case? (You may need to generate more data to answer this question.)
Remark: The program should take no input.
2) Matrix Multiplication
The performance of floating point operations is highly dependent on the code that's executing them. For example, if most of the operations are carried out on operands in level one cache, then the average performance will be far superior to that of code in which most operations are carried out on operands that need to be loaded from main memory. So we can't give a defnitive answer such as: "on machine X, the average runtime of a floating point operation is Y seconds." Undeterred by such practical considerations, though, we'll persevere. For our purposes, let's define the cost of a floating point operation to be the average run time of one of the operations in the multiplication of two N x N matrices. That is, suppose we compute the elapsed time of the following calculation:
A, B are matrices of size NxN with random entries.
for (i = 0; i < N; i++){
for (j = 0; j < N; j++) {
C[i][j] = 0.0;
for (k = 0; k < N; k++){
C[i][j] += A[i][k]*B[k][j];
}
}
}
Then the cost of a single floating point computation is (Elapsed Time)/2*N^3
Compute this cost for N = 1000.
Do not use MPI to do any parallelism here, but do use MPI_Wtime() to compare running times.
- How well did the least squares regression line fit the data? What was the correlation coefficient?
- Instead of using elapsed or wall-clock time, we might have used CPU time. Would this have made a difference to the times? Would it have given more accurate or less accurate times? Would it have had different effects on the reported times for the two different programs?
- Assuming your estimates are correct, what (if anything) can be said about the relative costs of communication and computation on the MPI cluster?
Remark: The program should take no input.
3) Random Walks
For this problem we will use point-to-point communication to simulate random walks on the cluster.

A basic random walk places a walker on the integer lattice inside of an interval [min, max] on the line. At each step the walker randomly moves forwards or backwards. If the walker goes out of bounds, it wraps back around. If you would like read more about random walks.
Parallel Domain Decomposition
When writing any parallel program the first task is usually to determine how to divide up the problem. Suppose the domain is given as [0, 20] and we have four processes. The domain should be split up like this.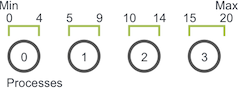
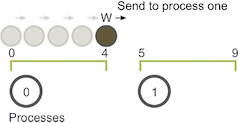
Implement this program and allow for a walker to move the right with probability p. However, at the head of your program, fix p=1. Do this to make it easy to determine that each processor can stop. Unless of course you can think of an easy way to determine this for arbitary p. (Without using other features of MPI).
Implementation Advice
- Use all of the programming practices you've learned in earlier classes, such as top-down design.
- Avoid deadlock by carefully ordering sends and receives
- Use MPI_Probe when receiving walkers.
- Write separate functions to handle sending and receiving walkers
- We have not yet seen how to send and recieve non standard data types, but to communicate an array of simple structs, we can use MPI_BYTE, as long as we calculate the length of our dataset appropriately.
4) Bitonic Sort
- Implement the bitonic sort algorithm described in class.
- Can you scale past what is doable on a single machine?
- Describe your implementation in words, both before, and after you write code, in writing.