Chapter 7
The Simple Recurrent Network: A Simple Model that Captures
the Structure in Sequences
Since the publication of the original pdp books (Rumelhart et al., 1986; McClelland
et al., 1986) and back-propagation algorithm, the bp framework has been developed
extensively. Two of the extensions that have attracted the most attention among
those interested in modeling cognition have been the Simple Recurrent Network
(SRN) and the recurrent back-propagation (RBP) network. In this and the next
chapter, we consider the cognitive science and cognitive neuroscience issues that have
motivated each of these models, and discuss how to run them within the PDPTool
framework.
7.1 BACKGROUND
7.1.1 The Simple Recurrent Network
The Simple Recurrent Network (SRN) was conceived and first used by Jeff Elman,
and was first published in a paper entitled Finding structure in time (Elman, 1990).
The paper was ground-breaking for many cognitive scientists and psycholinguists,
since it was the first to completely break away from a prior commitment to specific
linguistic units (e.g. phonemes or words), and to explore the vision that these units
might be emergent consequences of a learning process operating over the
latent structure in the speech stream. Elman had actually implemented
an earlier model in which the input and output of the network was a very
low-level spectrogram-like representation, trained using a spectral information
extracted from a recording of his own voice saying ‘This is the voice of the
neural network’. We will not discuss the details of this network, except to
note that it learned to produce this utterence after repeated training, and
contained no explicit feature, phoneme, syllable, morpheme, or word-level
units.
In Elman’s subsequent work he stepped back a little from the raw-stimulus
approach used in this initial unpublished simulation, but he retained the fundamental
commitment to the notion that the real structure is not in the symbols we as
researchers use but in the input stream itself. In Finding structure in time, Elman
presented several simulations, one addressing the emergence of words from a stream
of sub-lexical elements (he actually used the letters making up the words as the
elements for this), and the other addressing the emergence of sentences from a
stream of words. In both models, the input at any given time slice comes from
a small fixed alphabet; interest focuses on what can be learned in a very
simple network architecture, in which the task posed to the network is to
predict the next item in the sting, using the item at time t, plus an internal
representation of the state of a set of hidden units from the previous time
step.
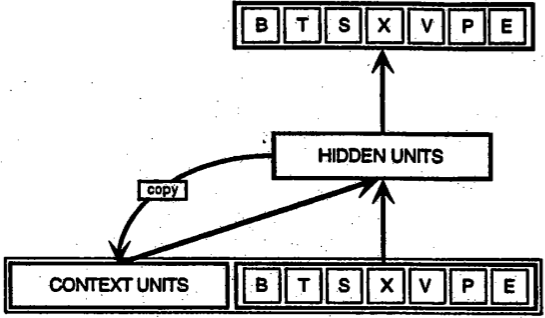
An SRN of the kind Elman employed is illustrated in Figure 7.1. We actually
show the network used in an early follow-up study by Servan-Schreiber et al. (1991),
in which a very small alphabet of elements is used (this is the particular network
provided with the PDPTool software, and it will be described in more detail
later).
The beauty of the SRN is its simplicity. In fact, it is really just a three-layer,
feed-forward back propagation network. The only proviso is that one of the two parts
of the input to the network is the pattern of activation over the network’s own hidden
units at the previous time step.
In Elman’s simulations, input to the network consisted of an unbroken stream of
tokens from the alphabet. The simulation starts with small random connection
weights in all feed-forward projections. The first token in the stream is presented,
typically setting the values of the units in the input layer to a pattern of ones
and zeros. Activation is propagated forward, as in a standard feed-forward
back-propagation network. The teaching input or target pattern for the output layer
is simply the next item in the stream of tokens. The output is compared to the
target, delta terms are calculated, and weights are updated before stepping along to
the next item in the stream. Localist input and output patterns are often used in
SRN’s, because this choice makes it easy from the modeler to understand the
network’s output, as we shall see later. However, success at learning and discovery of
useful and meaningful internal representations does not depend on the use of
localist input and output representations, as Elman showed in several of his
simulations.
After processing the first item in the stream, the critical step—the one that
makes the SRN a type of recurrent network—occurs. The state of the hidden
units is ‘copied back’ to the context units, so that it becomes available as
part of the input to the network on the next time step. The arrow labeled
‘copy’ in the figure represents this step. Perhaps it is worth noting that
this copy operation is really just a conceptual convenience; one can think
of the context units as simply providing a convenient way of allowing the
network to rely on the state of the hidden units from the previous time
step.
Once the copy operation is completed, the input sequence is stepped forward one
step. The input now becomes the item that was the target at the previous time step,
and the target now becomes the next item in the sequence. Activation is
propagated forward, the output is compared to the target, delta terms are
calculated via back-propagation, and weights are updated. Note that the
weights that are updated include those from the context (previous hidden
state) to the hidden units (current hidden state). This allows the network to
learn, not only to use the input, but also to use the context, to help it make
predictions.
In most of Elman’s investigations, he simply created a very long stream of tokens
from the alphabet, according to some generative scheme, and then repeatedly swept
through it, wrapping around to the beginning when he reached the end of the
sequence. After training with many presentations, he stopped training and tested the
network.
Here we briefly discuss three of the findings from Elman (1990). The first relates
to the notion of ‘word’ as linguistic unit. The concept ‘word’ is actually a
complicated one, presenting considerable difficulty to anyone who feels they must
decide what is a word and what is not. Consider these examples: ‘line drive’,
‘flagpole’, ‘carport’, ‘gonna’, ‘wanna’, ‘hafta’, ‘isn’t’ and ‘didn’t’ (often pronounced
“dint”). How many words are involved in each case? If more than one word, where
are the word boundaries? Life might be easier if we did not have to decide where the
boundaries between words actually lie. Yet, we have intuitions that there are points
in the stream of speech sounds that correspond to places where something ends
and something else begins. One such place might be between ‘fifteen’ and
‘men’ in a sentence like ‘Fifteen men sat down at a long table’, although
there is unlikely to be a clear boundary between these words in running
speech.
Elman’s approach to these issues, as previously mentioned, was to break
utternances down into a sequence of elements, and present them to an SRN. In his
letter-in-word simulation, he actually used a stream of sentences generated from a
vocabulary of 15 words. The words were converted into a stream of elements
corresponding to the letters that spelled each of the words, with no spaces. Thus, the
network was trained on an unbroken stream of letters. After the network had looped
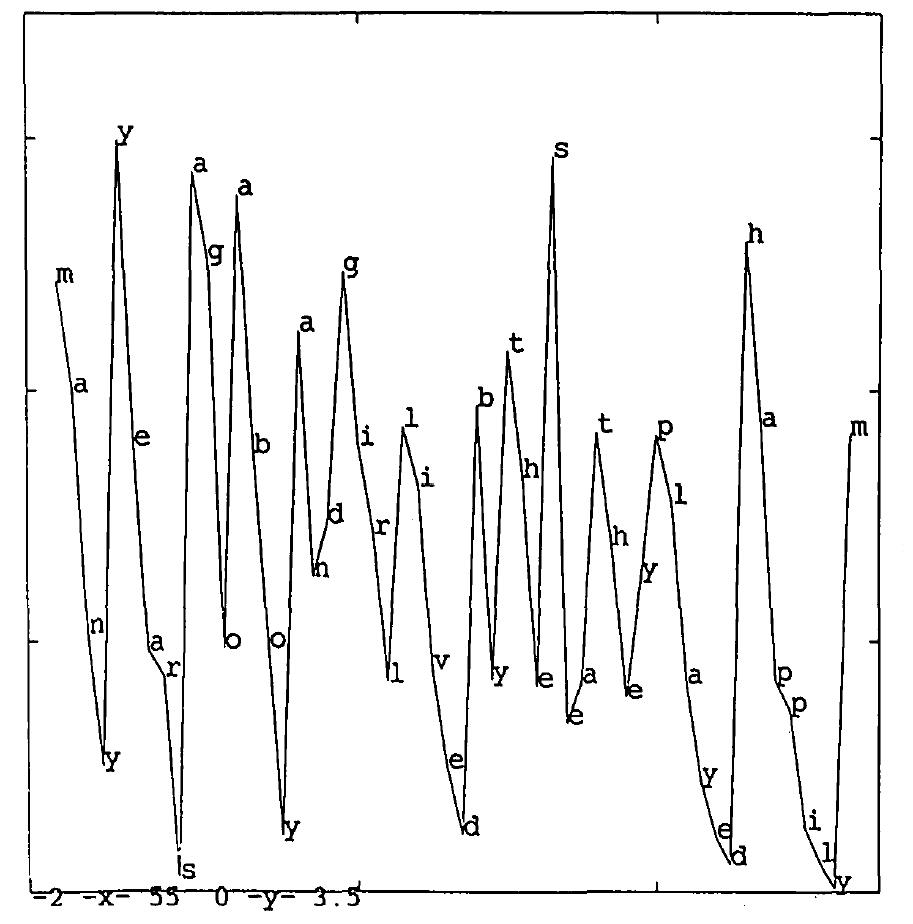
repeatedly through a stream of about 5,000 elements, he tested its predictions for
the first 50 or so elements of the training sequence. The results are seen in
Figure 7.2.
What we see is that the network tends to have relatively high prediction error for
the first letter of each word. The error tends to drop throughout the word, and then
suddenly to shoot up again at the first letter of the next word. This is not always
true – sometimes, afer a few downward steps, there is an uptick within a word, but
such uptics generally correspond to places where there might be the end of what we
ordinarily call a word. Thus, the network has learned something that corresponds at
least in part with our intuitive notion of ‘word’, without building in the concept
of word or ever making a categorical decision about the locations of word
boundaries.
The other two findings come from a different simulation, in which the elements of
the sequences used corresponded to whole words, strung together again to form
simple sentences. The set of words Elman used corresponded to several familiar
nouns and verbs. Each sentence involved a verb, and at least one noun as subject,
with an optional subsequent noun as direct object. Verbs and nouns fell into different
sub-types, – there were, for example, verbs of perception (which require an animate
subject but can take any noun as object) and verbs of consumption, which
require something consumable, and verbs of descruction, each of which had
different restrictions on the nouns that could occur with it as subject and
object. Crucially, the input patterns representing the nouns and verbs were
randomly assigned, and thus did not capture in any way the coocurrence
structure of the domain. Over the course of learning, however, the network came
to assign each input its own internal representation. In fact, the hidden
layer reflected both the input and the context; as a result, the patterns the
network learned to assign provided a highly context-sensitive form of lexical
representation.
The next two figures illustrate findings from this simulation. The first of these
(Figure 7.3) shows a cluster analysis based on the average pattern over the hidden
layer assigned to each of the different words in the corpus. What we see is
that the learned average internal representations indicate that the network
has been able to learn the category structure and even the sub-category
structure of the “lexicon” of this simple artificial language. The reason for this is
largely that the predictive consequences of each word correspond closely
to the syntactic category and sub-category structure of the language. One
may note, in fact, that the category structure encompasses distinctions that
are usually treated as syntactic (noun or verb, and within verbs, transitive
vs intransitive) as well as distinctions that are usually treated as semantic
(fragile-object, food item), and at least one distinction that is clearly semantic
(animate vs. inanimate) but is also often treated as a syntactically relevant
“subcategorization feature” in linguistics. The second figure (Figure 7.4) shows a
cluster analysis of the patterns assigned two of the words (BOY and GIRL) in
each of many different contexts. The analysis establishes that the overall
distinction between BOY and GIRL separates the set of context-sensitive patterns
into two highly similar subtrees, indicating that the way context shades the
representation of BOY is similar to the way in which it shades the representation of
GIRL.
Overall, these three simulations from Elman (1990) show how both segmentation
of a stream into larger units and assignment of units into a hierarchical similarity
structure can occur, without there actually being any enumerated list of units or
explicit assignment to syntactic or semantic categories.
Elman continued his work on SRN’s through a series of additional important and
interesting papers. The first of these (Elman, 1991) explored the learning of
sentences with embedded clauses, illustrating that this was possible in this simple
network architecture, even though the network did not rely on the computational
machinery (an explicitly recursive computational structure, including the ability
to ‘call’ a computational process from within itself) usually thought to be
required to deal with imbeddings. A subsequent and highly influential paper
(Elman, 1993) reported that success in learning complex embedded structures
depended on starting small – either starting with simple sentences, and gradually
increasing the number of complex ones, or limiting the network’s ability to
exploit context over long sequences by clearing the context layer after every
third element of the training sequence. However, this later finding was later
revisited by Rohde and Plaut (1999). They found in a very extensive series of
investigations that starting small actually hurt eventual performance rather than
helped it, except under very limited circumstances. A number of other very
interesting investigations of SRN’s have also been carried our by Tabor and
collaborators, among other things using SRN’s to make predictions about
participants reading times as they read word-by-word through sentences (Tabor
et al., 1997).
7.1.2 Graded State Machines
The simple recurrent network introduced by Elman (1990) also spawed investigations
by Servan-Schreiber et al. (1991). We describe this work in greater detail than some
of the other work following up on Elman (1990) because the exercise we provide is
based on the Servan-Schreiber et al. (1991) investigations.
These authors were especially interested in exploring the relationship between
SRNs an classical automata, including Finite State Transition Networks, and were
also interested in the possibility that SRNs might provide useful models of implicit
sequence learning in humans (Cleeremans and McClelland, 1991). Servan-Schreiber
et al. (1991) investigated the learning of sequences that could be generated by a
simple finite-state transition network grammar of the kind used to generate stimuli
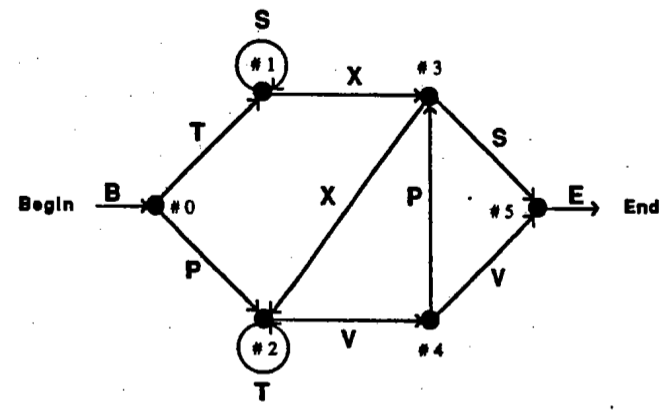
used in human implicit learning experiments by Rebur (1976), and illustrated in
Figure 7.5. Sequence generation occurs as follows. Each sequence begins with the
symbol ‘B’, and enters the state associated with the node in the diagram marked
‘#0’. From there, a random choice is made to follow one of the two links leading out
of node 0. After the random choice, the symbol written beside the link is added as
the second element of the sequence, and the process transitions to the state at the
end of the chosen link. The choice could, for example, be the upper link
leaving node 0, producing a T and shifting to node 1. The process iterates as
before, choosing one of two links out of the current node, adding the symbol
written next to the link as the next element of the seqeuence, and shifting
to the node at the end of the link. When node 5 is reached, there is only
one remaining possibility; the symbol E is written, and the sequence then
ends.
In their simulation of learning sequences generated by the Finite State Transition
Network, Servan-Schreiber et al. (1991) assumed that the learner is trained with a
series of sequences, which may be generated at random by the sequence-generating
finite-state transition network. At the beginning of each sequence, the context
representation is reset of a neutral initial state, and the initial element B is
presented on the input. The network then tries to predict the next element
of the sequence, which then is presented as the target. Small adjustments
to the weights are made, and then the process steps forward through the
sequence. Now the second element of the sequence (the one after the B) is
presented at the the input, and the third item in the sequence becomes
the target. The process of propagating activation forward, adjusting the
the connections, and stepping forward to the next element continues, until
the last element of the sequence (the E symbol) is reached. At that point,
processing of the sequence ends. The process then begins again with the next
sequence.
In their paper, Servan-Schreiber et al. (1991) demonstrated that a network like
the one shown in Figure 7.1 could essentially learn to become the transition network
grammar through a completely gradual and continuous learning process. That is, as a
result of training, the patterns at the hidden layer came to correspond closely to the
nodes of the finite state transition network, in the sense that there was essentially one
hidden pattern corresponding to each of the nodes in the network, regardless of the
sequence of elements leading to that node. However, the network could also
learn to ‘shade’ its representation of each node to a certain extent with the
details of the prior context, so that it would eventually learn to capture
subtle idiosyncratic constraints when trained repeatedly on a fixed corpus of
legal example sentences. The authors also went on to show that the network
could learn to use such subtle shading to carry information forward over an
embedded sequence, but this will only happen in the SRN if the material
needed at the end of the embedding is also of some relevance within the
sequence.
The reader is referred to the paper by Servan-Schreiber et al. (1991) for
further details of these investigations. Here we concentrate on describing the
simulation model that allows the reader to explore the SRN model, using the
same network and one of the specific training sets used by Servan-Schreiber
et al. (1991).
7.2 THE SRN PROGRAM
The srn is a specific type of back-propagation network. It assumes a feed-forward
architecture, with units in input, hidden, and output pools. It also allows for a
special type of hidden layer called a “context” layer. A context layer is a hidden layer
that receives a single special type of projection from another layer containing
the same number of units, typically a hidden layer. This special type of
projection (called a ‘copy-back projection’) allows the pattern of activation
left over on the sending units from the last input pattern processed to be
copied onto the receiving units for use as context in processing the next input
pattern.
7.2.1 Sequences
The srn network type also allows provides a construct called the “sequence”,
which consists of one or more input-output pairs to be presented in a fixed
order.
The idea is that one might experience a series of sequences, such that each
sequence has a fixed structure, but the order in which the sequences appear
can be random (permuted) within each epoch. In the example provided, a
sequence is a sequence of characters beginning with a B and ending with an
E.
Sequences can be defined in the pattern file in two different ways:
-
Default
- The default method involves beginning the specification of each
sequence with a pname, followed by a series of input-output pairs, followed
by ‘end’ (see the file gsm21_s.pat for an example). When the file is read,
a data structure element is created for the sequence. At the beginning of
each sequence, the state of the context units is initialized to all .5’s at
the same time that the first input pattern is presented on the input. At
each successive step through the sequence, the state of the context units
is equal to the state of the hidden units determined during the previous
step in the sequence.
-
SeqLocal
- The SeqLocal method of specifying a sequence works only for a restricted
class of possible cases. These are cases where (a) each input and target pattern
involves a single active unit; all other inputs and targets are 0; and (b) the
target at step n is the input at step n+1 (except for the last element of the
sequence). For such cases, the .pat file must begin with a line like
this:
SeqLocal b t s x v p e
This line specifies that the following entries will be used to construct actual
input output pattern pairs, as follows. The character strings following
SeqLocal are treated as labels for both the input and output units, with
the first label being used for the first input unit and the first output
unit etc. Single characters are used in the example but strings are
supported.
Specific sequences are then specified by lines like the following:
p05 b t x s e
Here each line begins with a pname, followed by a series of instances of the
different labels previously defined. The case shown above generates four
input-output pattern pairs; the first input contains a 1 in the first position and
0’s elsewhere and the first target contains a 1 in the second position and 0’s
elsewhere. The second input is the same as the first target, etc. Thus, in
this model the user specifies the actual symbolic training sequences
and these are translated into actual input and output patterns for the
user.
Using the last target from the previous sequence as the first element if the
input for the next sequence. If the first label in the string of labels is the special
label ‘#’, the last target pattern from the previous sequence is used as the first
input pattern for the current sequence. In this case, we also copy the
state of the hidden units from the network’s prediction of the last
target to the context layer, instead of resetting the context to the
clearval.
7.2.2 New Parameters
-
mu
- The srn program introduces one new parameter called mu. This parameter
specifies a scale factor used to determine how large a fraction of the pattern
of activation from the context layer at time step n is added to the pattern
copied back from the hidden layer. In the gsm simulation, mu is set to
0. Non-zero values of mu force some trace of the earlier context state to
stick around in the current state of the context units.
-
clearval
- At the beginning of each training and testing sequence, the activations
of the context units are set to the value of this parameter, represented as
clear value in the train and test options windows. By default, this paramter
is set to .5. If a negative value is given, the states of the units are not
reset at the beginning of a new sequence; instead the state from the last
element of the preceding sequence is used.
7.2.3 Network specification
The .net file specifies the specific architecture of the model as in other PDPtool
programs. To have a pool of units treated as a ‘context’ layer, it should be of type
‘hidden’ and should receive a single projection from some other layer (typically a
hidden layer) which has its constraint_type field set to ‘copyback’. When the
constraint type is ‘copyback’, there are no actual weights, the state of the ‘sending’
units is simply copied to the ‘receiving’ units at the same time that the next target
input is applied (except at the beginning of a new sequence, where the state of
each of the context units is set to the clearval, which by default is set to
.5).
7.2.4 Fast mode for training
The srn program’s inner loops have been converted to fast mex code (c code that
interfaces with MATLAB). To turn on the fast mode for network training, click the
’fast’ option in the train window. This option can also be set by typing the following
command on the MATLAB command prompt:
runprocess(’process’,’train’,’granularity’,’epoch’,’count’,1,’fastrun’,1);
There are some limitations in executing fast mode of training.In this mode,
network output logs can only be written at epoch level. Any smaller output frequency
if specified, will be ignored.When running with fast code in gui mode, network viewer
will only be updated at epoch level.Smaller granularity of display update is disabled
to speed up processing.
There is a known issue with running this on linux OS.MATLAB processes running
fast version appear to be consuming a lot of system memory. This memory
management issue has not been observed on windows. We are currently
investigating this and will be updating the documentation as soon as we find a
fix.
7.3 EXERCISES
The exercise is to replicate the simulation discussed in Sections 3 and 4 of
Servan-Schreiber et al. (1991). The training set you will use is described in more
detail in the paper, but is presented here in Figure 7.6. This particular set contains
21 patterns varying in length from 3 to 8 symbols (plus a B at the beginning and an
E at the end of each one).
To run the exercise, download the latest version of pdptool, set your path to
include pdptool and all of its children, and change to the pdptool/srn directory. Type
‘gsm’ (standing for “Graded State Machine”) at the matlab prompt. After everything
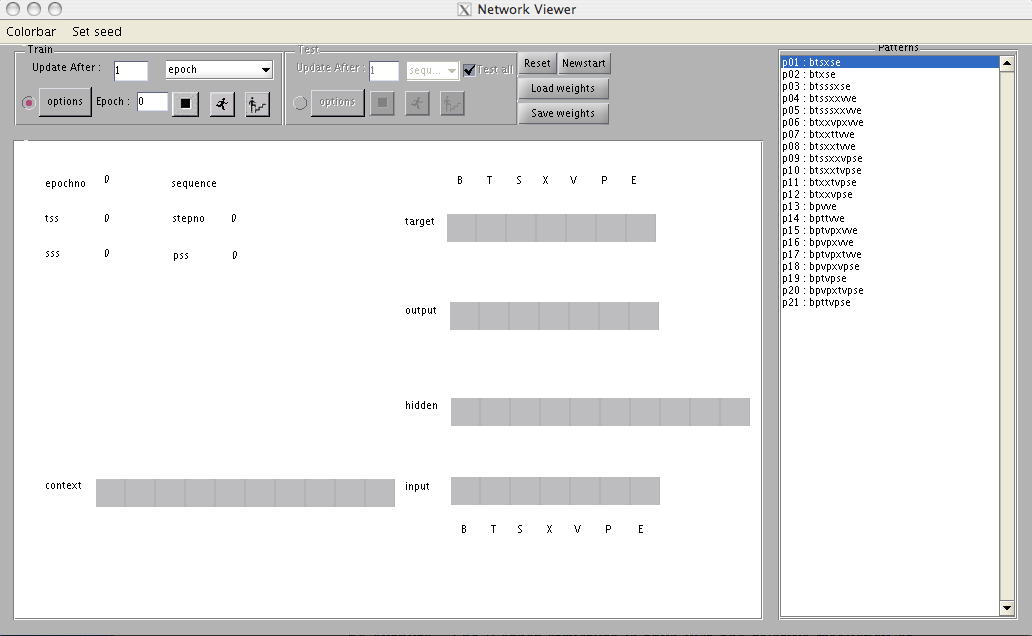
loads you will see a display showing (at the right of the screen) the input, hidden and
output units, and a vector representing the target for the output units (see Figure
7.7). To the left of the input is the context. Within the input, output, and target
layers the units are layed out according to Figure 7.1. Your exercise will be to
test the network after 10, 50, 150, 500, and 1000 epochs of training. The
parameters of the simulation are a little different from the parameters used in the
published article (it is not clear what values were actually used in the published
article in some cases), and the time course of learning is a little extended
relative to the results reported in the paper, but the same basic pattern
appears.
One thing to be clear about at the outset is that the training and testing is
organized at the sequence level. Each sequence corresponds to a string that could be
generated by the stochastic finite state automaton shown in Figure 7.5. The ptrain
option (which is the one used for this exercise) permutes the order of presentation of
sequences but presents the elements of the sequence in its cannonical sequential
order. Each sequence begins with a B and ends with an E, and consists of a variable
number N of elements. As describe above, the sequence is broken down into N-1
input-target pairs, the first of which has a B as input and the successor of
B in the sequence as its target, and the last of which has the next to last
symbol as its input and E as its target. When the B symbol is presented the
context is reset to .5’s. It makes sense to update the display during testing at
the pattern level, so that you can step through the patterns within each
sequence. During training I update the display at the epoch level or after 10
epochs.
Before you begin, consider:
- What is the 0-order structure of the sequences? That is, if you had no idea
about even the current input, what could you predict about the output?
This question is answered by noting the relative frequency of the various
outputs. Note that B is never an output, but all the other characters can
be outputs. The 0-order structure is thus just the relative frequency of
each character in the output.
- What is the 1st order structure of the sequences? To determine this
approximately, consult the network diagram (last page of this handout)
and note which letters can occur after each letter. Make a little grid four
yourself of seven rows each containing seven cells. The row stands for the
current input, the cell within a row for a possible successor. So, consulting
the network diagram, you will find that B can be followed only by T or P.
So, place an X in the second (T) cell of the first row and the 6th (P) cell
of the first row. Fill in the rest of the rows, being careful to attend to the
direction of the arrows coming out of each node in the diagram and the
label on each arc. You should find (unless I made a mistake) that three of
the letters actually have the exact same set of possible successors. Check
yourself carefully to make sure you got this correct.
OK, now run through a test, before training. You should find that the
network produces near uniform output over the output units at each step of
testing.
NOTE: For testing, set update to occur after 1 pattern in the test window. Use
the single step mode and, in this case, quickly step through, noticing how little the
output changes as a function of the input. The weights are initialized in a narrow
range, making the initial variation in output unit activation rather tiny. You can
examine the activations of the output units at a given point by typing the following
to the matlab console:
net.pool(5).activation
When you get tired or stepping through, hit run in the test window. The program
will then quickly finish up the test.
The basic goal of this exercise is to allow you to watch the network proceed to
learn about the 0th, 1st, and higher-order structure of the training set. You have
already examined the 0th and 1st order structure; the higher-order structure is the
structure that depends on knowing something about what happened before the
current input. For example, consider the character V . What can occur after a V ,
where the V is preceded by a T? What happens when the V is preceeded by an
X? By a P? By another V ? Similar questions can be asked about other
letters.
Q.7.0.3.
Set nepochs in the training options panel to ten, and run ten epochs
of training, then test again.
What would you say has been learned at this point? Explain your
answer by referring to the pattern of activation across the output
units for different inputs and for the the same input at different
points in the sequence.
Continue training, testing after a total of 50, 150, 500, and 1000
epochs. Answer the same question as above, for each test point point.
Q.7.0.4.
Summarize the time course of learning, drawing on your results for
specific examples as well as the text of section 4 of the paper. How do
the changes in the representations at the hidden and context layers
contribute to this process?
Q.7.0.5.
Write about 1 page about the concept of the SRN as a graded state
machine and its relation to various types of discrete-state automata,
based on your reading of the entire article (including especially the
section on spanning embedded sequences).
Try to be succinct in each of your answers. You may want to run the whole training
sequence twice to get a good overall sense of the changes as a function of
experience.