



Next: Ancestry Models
Up: Modelling decisions for the
Previous: Modelling decisions for the
Contents
How long to run the program
The program is started from a random configuration, and from there
takes a series of steps through the parameter space, each of which
depends (only) on the parameter values at the previous step. This
procedure induces correlations between the state of the Markov chain
at different points during the run. The hope is that by running the
simulation for long enough, the correlations will be negligible.
There are two issues to worry about: (1) burnin length: how long to
run the simulation before collecting data to minimize the effect of
the starting configuration, and (2) how long to run the simulation
after the burnin to get accurate parameter estimates.
To choose an appropriate burnin length, it is really helpful to look
at the values of summary statistics that are printed out by the
program (eg 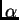 ,
, 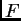 , the divergence distances among populations
, the divergence distances among populations
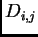 , and the likelihood) to see whether they appear to have
converged. I have found that in examples I have looked at, a burnin
of 10,000--100,000 is usually more than adequate.
To choose an appropriate run length, you will need to do several runs
at each
, and the likelihood) to see whether they appear to have
converged. I have found that in examples I have looked at, a burnin
of 10,000--100,000 is usually more than adequate.
To choose an appropriate run length, you will need to do several runs
at each 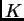 , possibly of different lengths, and see whether you get
consistent answers. Typically, you can get good estimates of the
parameter values (
, possibly of different lengths, and see whether you get
consistent answers. Typically, you can get good estimates of the
parameter values (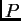 and
and 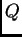 ) with fairly short runs (eg
10,000-100,000), but accurate estimation of
) with fairly short runs (eg
10,000-100,000), but accurate estimation of
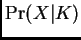 requires quite
long runs (perhaps
requires quite
long runs (perhaps 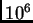 or more). In practice your run length may be
determined by your computer speed and patience as much as anything
else.
The front end provides time series plots of several key parameters.
You should look to see whether these appear to reach equilibrium
before the end of the burnin phase. If the values are still increasing
or decreasing at the end of the burnin phase, you need to increase the
burnin length.
If the estimate of varies greatly throughout the run (i.e.,
not just during the burnin), you may get more accurate estimates of
by increasing ALPHAPROPSD, which improves mixing in that
situation. (See a related issue in section 4).
or more). In practice your run length may be
determined by your computer speed and patience as much as anything
else.
The front end provides time series plots of several key parameters.
You should look to see whether these appear to reach equilibrium
before the end of the burnin phase. If the values are still increasing
or decreasing at the end of the burnin phase, you need to increase the
burnin length.
If the estimate of varies greatly throughout the run (i.e.,
not just during the burnin), you may get more accurate estimates of
by increasing ALPHAPROPSD, which improves mixing in that
situation. (See a related issue in section 4).
Next: Ancestry Models
Up: Modelling decisions for the
Previous: Modelling decisions for the
Contents
William Wen
2002-07-18