


Next: Estimating admixture proportions when
Up: Allele frequency models
Previous: Estimating :
Contents
We have modified our version of the correlated frequencies model from
Pritchard et al. (2000a). The implementation and interpretation of the
new ``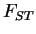 '' model will be described in detail in a forthcoming paper
by Falush et al. (2003). Brief details are provided below.
We introduce a new (multidimensional) vector,
'' model will be described in detail in a forthcoming paper
by Falush et al. (2003). Brief details are provided below.
We introduce a new (multidimensional) vector, 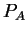 , which
records the allele frequencies in a hypothetical ``ancestral''
population. It is assumed that the
, which
records the allele frequencies in a hypothetical ``ancestral''
population. It is assumed that the 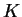 populations represented in our
sample have each undergone independent drift away from these ancestral
frequencies, at a rate that is parameterized by
populations represented in our
sample have each undergone independent drift away from these ancestral
frequencies, at a rate that is parameterized by
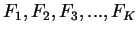 ,
respectively. The estimated
,
respectively. The estimated 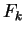 values should be numerically
similar to values, apart from differences that stem from the
slightly different model, and differences in estimation. Also, it is
difficult to estimate accurately for data with lots of
admixture.
is assumed to have a Dirichlet prior of the same form as that
used above for the population frequencies:
values should be numerically
similar to values, apart from differences that stem from the
slightly different model, and differences in estimation. Also, it is
difficult to estimate accurately for data with lots of
admixture.
is assumed to have a Dirichlet prior of the same form as that
used above for the population frequencies:
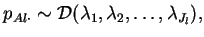 |
(1) |
independently for each 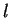 . Then the prior for the frequencies in
population
. Then the prior for the frequencies in
population 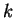 is
is
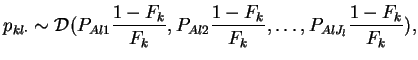 |
(2) |
independently for each and . In this model, the 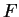 s have a
close relationship to the standard measure of genetic distance, .
In the standard parametrization of , the expected frequency in
each population is given by overall mean frequency, and the variance
in frequency across subpopulations of an allele at overall frequency
s have a
close relationship to the standard measure of genetic distance, .
In the standard parametrization of , the expected frequency in
each population is given by overall mean frequency, and the variance
in frequency across subpopulations of an allele at overall frequency
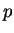 is
is
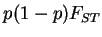 . The model here is much the same, except that we
generalize the model slightly by allowing each population to drift
away from the ancestral population at a different rate (), as
might be expected if populations have different sizes. We also try to
estimate ``ancestral frequencies'', rather than using the mean
frequencies.
We have placed independent priors on the , proportional to a
gamma distribution with means of 0.01 and standard deviation 0.05 (but
with
. The model here is much the same, except that we
generalize the model slightly by allowing each population to drift
away from the ancestral population at a different rate (), as
might be expected if populations have different sizes. We also try to
estimate ``ancestral frequencies'', rather than using the mean
frequencies.
We have placed independent priors on the , proportional to a
gamma distribution with means of 0.01 and standard deviation 0.05 (but
with
![$ {\rm Pr}[F_k\geq1]=0$](img121.png) ). The parameters of the gamma prior can be
modified by the user. Some experimentation suggests that the prior
mean of 0.01, which corresponds to very low levels of subdivision,
often leads to good performance for data that are difficult for the
independent frequencies model. In other problems, where the
differences among populations are more marked, it seems that the data
usually overwhelm this prior on .
). The parameters of the gamma prior can be
modified by the user. Some experimentation suggests that the prior
mean of 0.01, which corresponds to very low levels of subdivision,
often leads to good performance for data that are difficult for the
independent frequencies model. In other problems, where the
differences among populations are more marked, it seems that the data
usually overwhelm this prior on .
Next: Estimating admixture proportions when
Up: Allele frequency models
Previous: Estimating :
Contents
Jonathan Pritchard
2003-07-10