


Next: Printout of when using
Up: Interpreting the text output
Previous: Output to screen during
Contents
Label (%Miss) Pop: Inferred clusters (and 90% probability intervals)
1 17 (0) 2 : 0.977 0.023 (0.829,1.000) (0.000,0.171)
2 1219 (7) 2 : 0.997 0.003 (0.988,1.000) (0.000,0.012)
3 1223 (0) 2 : 0.833 0.167 (0.003,1.000) (0.000,0.997)
4 1329 (7) 1 : 0.005 0.995 (0.000,0.020) (0.980,1.000)
5 15 (0) 3 : 0.006 0.994 (0.000,0.016) (0.984,1.000)
When the program is run without using prior population information,
the results for 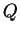 are presented in the format shown above (here
are presented in the format shown above (here 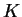 was set to 2). This is read as follows. Reading from row 1:
Individual label (taken from data file) = 17; percentage of missing
data for this individual = 0%; user-assigned population = 2;
estimated membership in clusters 1 and 2 = 0.977 and 0.023
respectively (these are the mean values of
was set to 2). This is read as follows. Reading from row 1:
Individual label (taken from data file) = 17; percentage of missing
data for this individual = 0%; user-assigned population = 2;
estimated membership in clusters 1 and 2 = 0.977 and 0.023
respectively (these are the mean values of 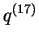 ); 90%
probability intervals on
); 90%
probability intervals on
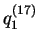 and
and
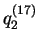 are
(0.829,1.000) and (0.000,0.171), respectively. (Note that the
probability intervals are shown only if ANCESTDIST is turned on.)
are
(0.829,1.000) and (0.000,0.171), respectively. (Note that the
probability intervals are shown only if ANCESTDIST is turned on.)
Jonathan Pritchard
2003-07-10