This small project will use a dict data structure for a text algorithm with some whimsy to it. The program will be able to produce a random imitation of any source text. The code is short but very algorithmic.
The file mimic.zip has the mimic project directory. For this project, the handout will outline the problem to solve. The file "mimic.py" is included as a starting point, but it is basically blank, so you are practicing creating and testing code from scratch. This project does not require map/lambda.
Given a text, we'll say the "bigrams" data records what words come immediately after other words in the text. For example the text:
This and that and the other.
Yields the bigrams:
'This' → 'and' 'and' → 'that', 'the' 'that' → 'and' 'the' → 'other.'
In the text, 'This' is followed only by 'and', but 'and' is followed by both 'that' and 'the'.
For every pair of adjacent words in the text, call them First and Second. The bigrams dict has a key in it for every First word in the text. The value for each First in the dict is a list of all the Second words for that First (duplicates are allowed in the list). As a one-off addition, the empty string '' is treated as being First before the very first word. So for example the text 'This and that and the other.' yields the following bigrams dict:
{
'': ['This'],
'This': ['and'],
'and': ['that', 'the'],
'that': ['and'],
'the': ['other.'],
}
To build the bigrams structure, loop through all the words in the text, keeping track of both the word and the previous word for each iteration. This table shows the 6 loops required to go through the 6 words of 'This and that and the other.':
LOOP WORD PREVIOUS 1 This '' 2 and This 3 that and 4 and that 5 the and 6 other. the
Each time through the loop, use the previous/word pair to update the bigrams dict.
Here's a bit of the bigrams of the Gettysburg address:
{
'': ['Four'],
'Four': ['score'],
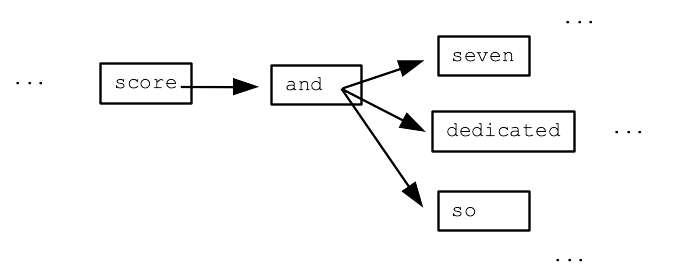
'score': ['and'],
'and': ['seven', 'dedicated', 'so', 'proper', 'dead,', 'that'],
'seven': ['years'],
...
}
The word 'Four' only has the word 'score' after it, but the word 'and' has many words which appear after it.
For any particular word, the bigrams data encodes what words might come after it. What is the bigrams data good for? One neat application is chasing through the bigrams structure, creating a random text that mimics the original text. Here is an outline of the algorithm to generate a n words of mimic text from the bigrams:
print(word + ' ', end='')
print() to add one '\n' at the end
Here is some mimic output text based on the gettysburg address. It has a feverish quality, somehow echoing the words and tone of the original but without completely making sense.
Four score and dedicated to the living, rather, to the great civil war, testing whether that all men are met on a great task remaining before us to dedicate a great battle-field of that we can not have come to add or any nation so nobly advanced. It is for By default, the mimic program produces 50 word outputs, and there's a command line option to specify any number. The output ends with word 50, so like the above example, the ending tends to be abrupt.
Here we have 100 words from the declaration of independence:
When in the earth, the Laws of mankind requires that among the earth, the separate and equal station to the causes which have connected them with another and of the separate and to which the opinions of Nature's God entitle them, a decent respect to the powers of mankind requires that they are created equal, that all men are Life, Liberty and the pursuit of mankind requires that they are Life, Liberty and the powers of Nature and of human events it becomes necessary for one people to the powers of Nature and of Nature and equal station to assume
Someday perhaps you can adapt this work to get a grant as an experimental computer literature artist. But for now in CS106A, this amounts to less than one page of Python code!
Aside: you are building what is known as a "Markov Model": imagine each word is a node with arrows leading out of it to each possible next word. The algorithm randomly chases through this network, picking a random arrow out of a node for each hop.
For this assignment, we outline what the program needs to do, but you decompose your own functions and code. The requirement is that you decompose your program into three or more functions (counting main() as one function), and these functions fit together to solve the whole problem. We will not be super picky about the exact decomposition of the functions. They just need to be proper black-box functions and work together to solve the whole problem.
Very often in CS106A programs, there are functions that read a file and return a data structure, and later functions take in that data structure as a parameter for further computation or printing. (The wordcount.zip lecture example has this structure.)
{'': ['a'], 'a': ['b', 'c', 'd.'], 'b': ['a'], 'c': ['a']}
with open(filename) as f:
text = f.read() # reads entire file into 1 string
words = text.split() # split text into list of word strings
open(filename, encoding='utf-8')
$ python3 mimic.py gettysburg.txt
$ python3 mimic.py gettysburg.txt 200
When it's working, try making longer random texts from from "alice-book.txt" and "independence.txt" and "apple-license.txt", like this:
$ python3 mimic.py apple-license.txt 200
Once your code is cleaned up and works right, please turn in your mimic.py file on Paperless as usual. That's nice looking python project - creating neat output with not much code.
A standard code-pattern that comes up sometimes is to loop through elements as usual, but for each element, the code also has access to what the previous element was. The standard solution is to introduce a "previous" variable, give it an initial value, and then at the bottom of the loop, assign previous to the current value, so it's ready for the next iteration.
Here's the technique in a for/range loop
previous = -1 # set special previous value for the very first elem
for i in range(100):
# in here, use i and previous
print(previous, i)
# at the end of the loop, set previous for next iteration
previous = i
The Python "random" module contains functions which provide pseudo-random numbers. For this program, call the random.choice() function which returns, at random, one element from a non-empty list. The needed "import random" is provided at the top of the starter file.
>>> import random >>> lst = ['a', 'b', 'c'] >>> random.choice(lst) 'a' >>> random.choice(lst) 'b' >>> random.choice(lst) 'a'