Slide 1
Today: string in, string upper/lower, if/elif, string .find(), slices
Some of today's material is review.
See chapters in Guide:
Slide 2
Announcements
- Assignment 3, Sand! has been released, and is due next Tuesday.
- The first quiz is next Monday. It will cover Bit problems and image problems. The best study materials are:
- The expermental server Bit and Image problems
- Section 1 and 2 problems
Slide 3
String in Test
- String
in- test if a substring appears in a string - Chars must match exactly - upper/lower are considered different
- This is True/False test - use
.find()(below) to know where substring is - Mnemonic: Python re-uses the word "in" from the for loop
- Style: don't write code for something that Python has built-in
>>> 'c' in 'abcd'
True
>>> 'bc' in 'abcd' # works for multiple chars
True
>>> 'bx' in 'abcd'
False
>>> 'A' in 'abcd' # upper/lower are different
False
Slide 4
Strategy: Built In Functions
Python has many built-in functions, and we will see all the important ones in CS106A. You want to know the common built-in functions, since using a built-in is far preferable to writing code for it yourself - "in" is a nice example. The "in" test for several data structure to see if a value is in there. This is our first example with strings.
Slide 5
Example: has_pi()
has_pi(s): Given a string s, return True if it contains the substrings '3' and '14' somewhere within it, but not necessarily together. Use "in".
> has_pi()
Note these functions are in the string-3 section on the Experimental server
Slide 6
boolean-test AND boolean-test
This form works in English but not in Python:
if '3' and '14' in s: # NO does not work
...
The and should connect two fully formed boolean tests, such as you would write with "in" or "==", so this works
if '3' in s and '14' in s:
...
This problem has a one-liner solution that doesn't even use if:
return '3' in s and '14' in s
Slide 7
Practice: has_first()
Slide 8
Recall: String += Accumulate Pattern
result = ''- at startresult += xxxxx- in loopreturn result- at end
Slide 9
String Character Classes
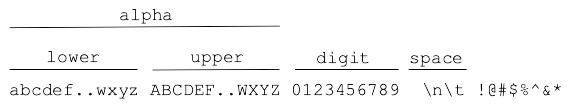
- Strings are made of characters, chars
- Chars are divided into "classes"
- "alpha" - alphabetic "word" chars, e.g. a-z
Other non-roman alphabets, have their own alphabetic chars - "digit"" - 0-9
- "space" - space, tab, newline
- Python char test functions
Work on 1 or more chars
Returns True if true for all chars
False for the empty string - s.isdigit() - is digit char
- s.isalpha() - is alphabetic char
- s.isspace() - is space char
- Space is mentioned for completeness, we'll concentrate on alpha and digit
>>> 'a'.isalpha()
True
>>> 'cat'.isalpha()
True
>>> '5'.isalpha()
False
>>> '5'.isdigit()
True
>>> '@'.isalpha()
False
Slide 10
Uppercase / Lowercase chars
- In some languages, alpha chars can have upper/lower pairings
'a'is the lowercase form of'A'
'A'is the uppercase form of'a' s.upper()- returns uppercase form of ss.lower()- returns lowercase form of s- Immutable:
s.upper()returns a new, converted string
The original string s is unchanged s.isupper()- True if made of uppercase charss.islower()- True if made of lowercase chars- A char with no upper/lower difference, e.g.
'@'or'2'
Not changed by upper()/lower()
isupper()/islower() return False
>>> 'Kitten123'.upper() # return with all chars in upper form
'KITTEN123'
>>> 'Kitten123'.lower()
'kitten123'
>>>
>>> 'a'.islower()
True
>>> 'A'.islower()
False
>>> 'A'.isupper()
True
>>> '@'.islower()
False
>>> 'a'.upper()
'A'
>>> 'A'.upper()
'A'
>>> '@'.upper()
'@'
>>> s = 'Hello'
>>> s.upper() # Returns uppercase form of s
'HELLO'
>>>
>>> s # Original s unchanged
'Hello'
>>>
Slide 11
Example: alpha_up()
'12abc34' -> 'ABC'
Given string s. Return a string made of all the alphabetic chars in s, converted to uppercase form.
Use string functions .isalpha() and .upper()
Solution
def alpha_up(s):
result = ''
for i in range(len(s)):
if s[i].isalpha():
result += s[i].upper()
return result
Slide 12
Example: catty()
> catty()
'xCtxxxAax' -> 'CtAa'
Return a string made of the chars from the original string, whenever the
chars are one of 'c' 'a' 't', (either lower or upper case). So the
string 'xaCxxxTx' returns 'aCT'. (Had an earlier version of this
function that was case-sensitive.)
Slide 13
Catty Version That Doesn't Work - V1
Here is a natural way to think of the code, but it does not work:
def catty(s):
result = ''
for i in range(len(s)):
if s[i] == 'c' or s[i] == 'a' or s[i] == 't':
result += s[i]
return result
What is the problem? Upper vs. lower case. We are not getting any
uppercase chars 'C' for example.
Slide 14
Catty Solution V2
Solution: convert each char to lowercase form .lower(), then test.
Solution - this works, but that if-test is ugly
def catty(s):
result = ''
for i in range(len(s)):
if s[i].lower() == 'c' or s[i].lower() == 'a' or s[i].lower() == 't':
result += s[i]
return result
Slide 15
Idea: Decomp By Var
- The code is getting a little lengthy
- The repeated
s[i].lower()is irksome - Introduce a variable to hold a commonly used value
- Advantages
- 1. Shorten the code, less repetitive typing
- 2. Variable name helps the code "read" better
- 3. A sort of decomp within a function - break the big thing into little steps
Slide 16
Decomp Var Steps
- Some phrase X repeated in code
e.g.s[i].lower() - Used several times, or it's just wordy to type
- Create a variable, compute once and store
low = s[i].lower() - Use that variable on later lines
- Variable name noun - code "reads" better
- Aside: can name the var anything, and the code still works
Slide 17
Catty Solution V3 - Better
Create variable to hold the lengthy computation - shorter code and "reads" better.
low = s[i].lower()
The complete solution
def catty(s):
result = ''
for i in range(len(s)):
low = s[i].lower() # decomp by var
if low == 'c' or low == 'a' or low == 't':
result += s[i]
return result
Style aside: the name of a variable should remind us of the role of that data in the local code. Other than that, the name can be short. The name does not need to repeat every true thing about the value. Just enough to distinguish it from other values in this algorithm.
Good names, short but including essential details: low, low_char
Names with more detail, probably too long: low_char_i, low_char_in_s
The V2 code above is acceptable, but V3 is shorter and nicer. The V3 code also runs faster, as it does not compute the lowercase form three times per char.
Slide 18
if/elif Structure
- An extra "if" feature, not used so often
- if/elif - a series of if-tests
- Evaluate test1, test2, test3
- As soon as test is true
Runs that action
Exits the if/elif structure
No further tests/actions will run - Optional "else:" at end runs if no test is true
- The plain if-statement is used most often
- Only use this form when you have a series of tests
- Mnemonic: "else" and "elif" are the same length
if test1:
action-1
elif test2:
action-2
else:
action-3
Slide 19
Example: str_adx()
str_adx(s): Given string s. Return a string of the same length. For every alphabetic char in s, the result has an 'a', for every digit a 'd', and for every other type of char the result has an 'x'. So 'Hi4!x3' returns 'aadxad'. Use an if/elif structure.
- If/elif logic to check for different char types
- alpha char → 'a', digit → 'd', otherwise → 'x'
- e.g. 'Z5$$t' → 'adxxa'
Solution
def str_adx(s):
result = ''
for i in range(len(s)):
if s[i].isalpha():
result += 'a'
elif s[i].isdigit():
result += 'd'
else:
result += 'x'
return result
Slide 20
String find()

s.find(target_str)– searchsfortarget_str- Returns int index where found first, searching from start of
s - Returns
-1if not found Important! - Alternate form: 2nd "start_index" parameter, starts search from
there
s.find(target_str, start_index)(use this later)
>>> s = 'Python'
>>> s.find('t')
2
>>> s.find('th')
2
>>> s.find('n')
5
>>> s.find('x')
-1
>>> s.find('N')
-1
Slide 21
Strategy: Dense = Slow Down
- Some lines of code are routine
- Require just normal attention
- An advantage of using idiomatic phrases
for i in range(len(s)): - But some lines are dense
- Slow down for those, work carefuly
- Slices (below) are dense!
- Dense = Powerful!
Slide 22
Python String Slices
- This is a fantastic feature
- "substring" - contiguous sub-part of a string
- Access substring with 2 numbers
- "slice" uses colon to indicate a range of indexes
s[1:3]returns'yt'- Start at first number
- Up to but not including second number UBNI
s[3:3]= empty string
"Not including" dominates the "starting at"- Try it in the interpreter
- Style: typically written with no spaces around ":"
>>> s = 'Python'
>>> s[1:3] # 1 .. UBNI
'yt'
>>> s[1:5]
'ytho'
>>> s[4:5]
'o'
>>> s[4:4] # "not including" dominates
''
Slide 23
Omit Start/End Index
- If start index is omitted, goes from start of string
- If end index is omitted, goes through end of string
- If number is too big .. uses end also
- Note perfect split: s[:4] and s[4:]
Number used as both start and end
Splits the string into 2 pieces exactly
>>> s[:3] # omit = from/to end
'Pyt'
>>> s[4:]
'on'
>>> s[4:999] # too big = through the end
'on'
>>> s[:4] # "perfect split" on 4
'Pyth'
>>> s[4:]
'on'
>>> s[:] # the whole thing
'Python'
Slide 24
Example: brackets()
A first venture into using index numbers and slices. Many problems work in this domain - e.g. extracting all the hashtags from your text messages.
'cat[dog]bird' -> 'dog'
> brackets
- Problem spec: either 2 brackets, or zero brackets
- Strategy:
- Use s.find()
left = s.find('[')
right = s.find(']') - Switch between drawing and code
- Decomp by var
Store in variableleftfor later lines
Nice to have wordsleftandrightin code narrative - Look for right bracket
- Use slice to pull out and return answer
Slide 25
Brackets Drawing
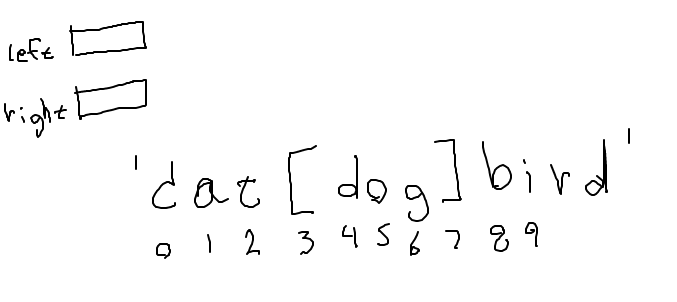
Slide 26
Brackets Observations
- Make a drawing - work out the index numbers
- Diagram / example strategy
- Code should work in general
- BUT can use specific string to work out numbers
- e.g.
'cat[dog]bird' - Empty string input - works?
- What about input
'a[]z'
Verify that our slice works here too
Solution
def brackets(s):
left = s.find('[')
if left == -1:
return ''
right = s.find(']')
# Use slice to pull out chars between left/right
# make a drawing!
return s[left + 1: right]
Slide 27
Brackets - Decomp By Var
The variables left and right make this code more readable. They work
naturally in the drawing and in the code, naming an important
intermediate value that runs through the computation.
Below is what the code looks like without the variable. It works fine, and it's one line shorter, but the readability is a worse. It also likely runs a little slower, as it computes the left-bracket index twice.
def brackets(s):
if s.find('[') == -1:
return ''
return s[s.find('[') + 1: s.find(']')]
Our brackets solution with its variables looks better.
Slide 28
Aside: Off By One Error
Int indexing into something is extremely common in computer code. So of course doing it slightly wrong is very common as well. So common, there is a phrase for it - "off by one error" or OBO — it even has its own wikipedia page. You can feel some kinship with other programmers each time you stumble on one of these.
"My code is perfect! Why is this not working? Why is this not work ... oh, off by one error. We meet again!"
Slide 29
Practice: at_3()
Here is a problem similar to brackets for you to try. If we have enough time in lecture, we'll do it in lecture. A drawing really helps the OBO on this one.
> at_3
Slide 30
Optional: Negative Slice

- We'll cover this someday maybe
- Optional / advanced shorthand
- Handy to refer to chars at end of string instead of beginning
- Negative numbers to refer to chars at end of string
- -1 is the last char
- -2 is the next to last char
- Works in slices etc.
- Maybe just memorize this one:
s[-1]is the last char in s
>>> s = 'Python'
>>> s[len(s)-1]
'n'
>>> s[-1] # -1 is the last char
'n'
>>> s[-2]
'o'
>>> s[-3]
'h'
>>> s[1:-3] # works in slices too
'yt'
>>> s[-3:]
'hon'
>>> s[:-1] # return all but the last characer (used very often!)