
Today: Last lecture, your future in CS, conclusions
I'm happy to talk to people after class at Bytes cafe with any sort of CS questions, then heading over to Durand. (Office hours 2-3 merged into this). Also on Zoom at 3:10 for remote people.
I'm gradually working on and expanding the Python Guide, aiming to keep it as a free resource on the web. If you want to find it in the future, it's linked from my home page and the CS106A page.
I'm going to take 10 minutes to show you something of interest for your future. At the beginning it will look like an innocent Python talk, and it some point it will transition to something you have heard about.
This and that and the other.
It's linear - can scan it from first word to last.
For each word in the text, we could note which words come after it, essentially the pairs of words in the text sequence, aka "bigrams". We could build a Python structure, where each word is a key, and its value is a list of all the words that come after that word at some point in the text. As a special case, we'll say the empty string appears before the very first word of the text.
{
'': ['This'],
'This': ['and'],
'and': ['that', 'the'],
'that': ['and'],
'the': ['other.'],
}
Four score and seven years ago our fathers brought forth on this continent, a new nation, conceived in Liberty, and dedicated to the proposition that all men are created equal. ...
And here is what some of the bigrams for the gettysburg address:
{
'': ['Four'],
'Four': ['score'],
'score': ['and'],
'and': ['seven', 'dedicated', 'so', 'proper', 'dead,', 'that'],
'seven': ['years'],
'dedicated': ['to', 'here', ...],
...
}
The bigrams structure of the text is .. what is it? It's a sort of a summary. It does not replicat the text, but it has much of the text distilled into it. We might call it a "model of the text. The word "model" appears frequently in computer systems that are trying to work with masses of real data.
We could use the model to generate random text that is loosely based on the input text.
Algorithm - "chase" through the bigrams to create text.
1. Start with a word, e.g. "Four" to start. This is the first word of the output.
2. Look at the list of words that come after it.
3. Choose one of those words at random as the next word. Repeat.
Output: Four score and dedicated here ...
Here are some random output from the Gettysburg bigrams. They do not make a ton of sense, but you can see how the model is replaying bits of the original, a weak copy of the original human authorship.
1. Four score and dedicated here highly resolve that all men are created equal. Now we can never forget what we can not dedicate a final resting place for us -- that nation so conceived in Liberty, and so nobly advanced. It is rather for the proposition that all men are created equal.
2. Four score and so nobly advanced. It is rather for those who struggled here, have thus far above our fathers brought forth on this continent, a great battle-field of devotion -- that we should do this. But, in Liberty, and dead, who here have consecrated it, far above our fathers brought forth on this continent, a final resting place for which they gave the unfinished work which they gave the people, for which they who fought here highly resolve that these dead we say here, have thus far above our poor power to add or detract.
Gettysburg is so short, it really limits how well the model can do. Try some longer texts.
Alice's elbow against herself, to queer things -- at once tasted -- at once, with an atom of the house down!' said the Dodo, `the best plan.' It was the Mock Turtle at the OUTSIDE.' He unfolded the way through all like that!' screamed the glass table set to speak severely to twenty at this, that was peering about ravens and ending with its voice.
A wonderful quickness, and beautiful. “Eighteen years!” said Mr. Barsad was coming and table, covered by Madame Defarge was sleep or less—he stationed Miss Pross and alluvial mud, to themselves to use them,' I was present. Let me where anything to her, on Carton. Some of things to do you to-night.
Model distills some of the sense of the original
Can create kind of lame echo - re-mixing elements from the original. It's pretty good considering that all it does is look at pairs of words.
Does not have intelligence. It is remixing/replaying elements from the original.
This gives it the appearance of intelligence, since it is remixing something written with intelligence.
If our bigrams code is like a rollerskate, then Chat GPT is like a 747. Chat GPT, at a guess, is the product of 10 PhDs working for 10 years.
The important similarity is that you have a human, intelligently created body of work. The computer absorbs this into a model.
Two predictions - a bad one and a good one. Let's do the bad one first.

Say we have an author, and they create some content on the web that is good - using their human intelligence. Say it's a recipe.
Google finds this page, and shows it to you when you are searching for that, plus puts some ads around it. This model can be pretty great, making a lot of knowledge available.
Note that Google algorithm is trying to show you the best page. Google does not have a nefarious purpose to show you a not-great page. But it's just an algorithm.
Search Engine Optimization
The idea is that people create knock-offs or just copies of the original good content, cover them with extra ads. The knock-offs are optimized to appeal to the google algorithm, sort of cat-vs-mouse as google tweaks the algorithm to try to favor the good content, and the SEO pages tweak to match the new algorithm. Note that the SEO pages are not necessarily the best for the end user. They are optimized to fool the Google algorithm. That's why it is called: Search Engine Optimization.
I'm sure you have seen SEO type pages when you are looking for something. Often the do have the answer in there, but with lots of ads and click-through. You kind of miss the regular old page that had the answer, and wonder where it went.
I believe Chat GPT will supercharge the SEO downsides of the internet. I fear the technology makes it so cheap to semi-plagiarize content, filling the internet with many not-best quality knockoffs.
Theme: sub-reddit type discussions are an often-overlooked part of the value of the internet.
Suppose you are trying to read people's opinions in a sub-reddit about mechanical keyboards, or knitting needles, or kittens, or whatever. Seeing the opinions of other random people can be fantastic, and reddit is a great example.
But the bad scenario here is that GPT fills the domain with a blizzard of fake, biased information, or trolling, it's hard to find the actual opinion.
Now Google and Amazon and Reddit are not powerless here, but they are going to have to work at it. A valuable feature of content may be that you know it has a real human, unbiased author. Perhaps there will be a shift to knowing about the author vs. just the content itself.
Many sentences or bits of code to write, look like other sentences and bits of code. I expect Chat GPT type technology will appear where we are authoring as a sort of co-pilot or super auto-correct. A bit like spelling correction now - a helper filling things in, so we get work done quicker.
This is definitely going to happen, and I expect we will be better off for it.
That's our Chat GPT futurism discussion. Now let's talk about CS106A and later courses.
You will never not know this nature of the computer.
I imagine 20 years from now, you are playing trivia with friends, and the word "concatenate" or "off by one error" comes up, and it's all going to come back to you.
No!
Here is the deal: Python and the space of all programming techniques is very large. A bigger space than you might think.
You have learned the most important 80% core: loops, lists, strings, functions, tests, files
There's a few more important techniques in CS106B. Most programs, even very advanced programs, are centered around those core features. If you need to use a less-common technique, you may look it up and figure out as you go. That's how most programmers proceed - the core they know well, the other stuff they look up as they go.
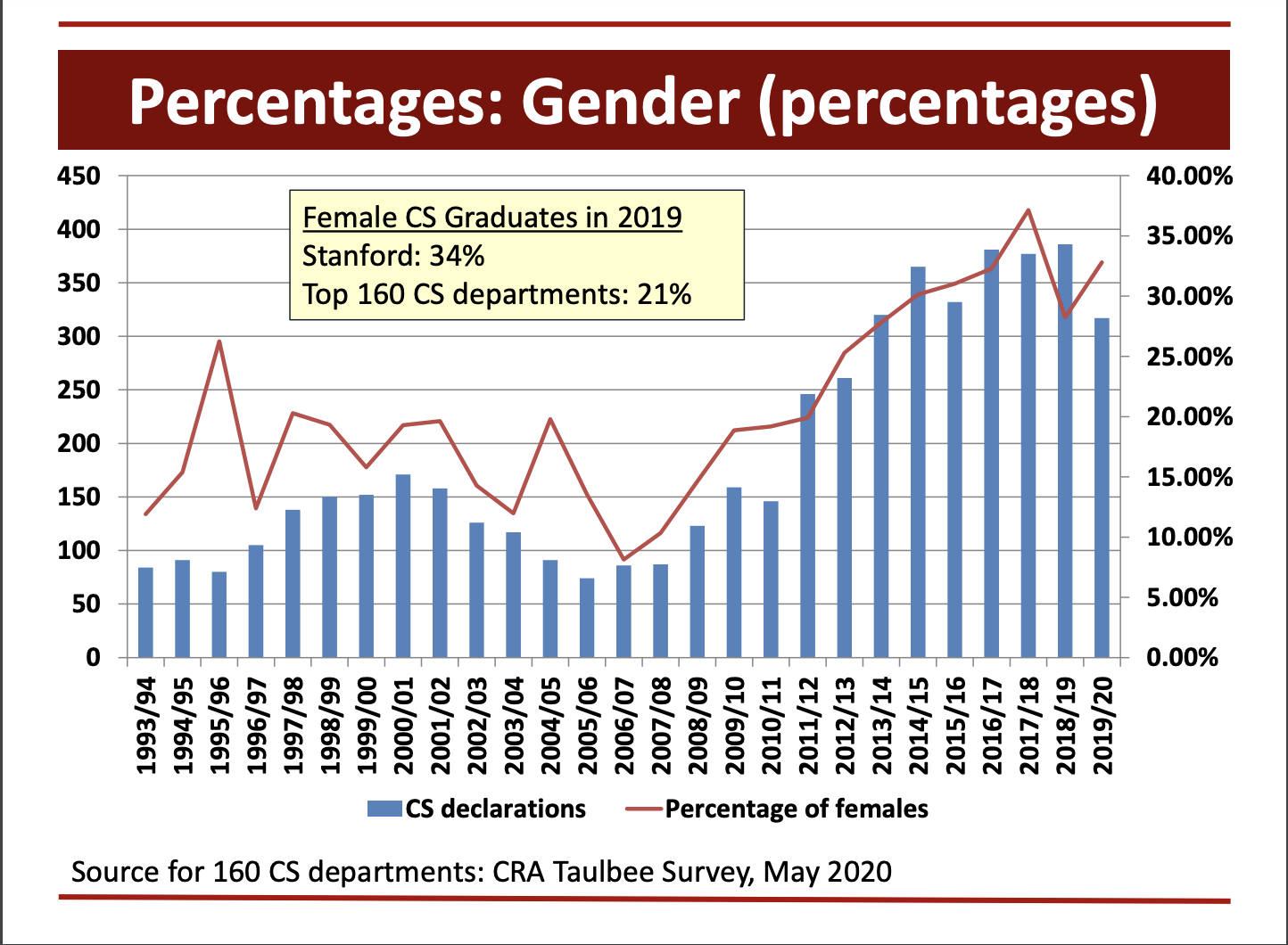
Slide from Mehran Sahami, Stanford CS-Education. The bars is number of students. The line is the percentage of women. Both are going up which is great, and it looks like a gradual broadening of the field.
I was on a bicycle, wearing ratty clothes and a "Python" t-shirt stopped for a red light. A person walking in the cross-walk in front of me, stopped, turned to me, and asked if I was looking for work.
Not to disillusion you about graduating from Stanford, but that is not how hiring is normally done.
Like how desperate for programmers was that person? That is what an extreme programmer shortage looks like!
No. For the last 30 years in Silicon valley. There have been perhaps 3 1-year stretches where demand for programmers fell. The other 27 years were dominated by white-hot, very strong demand for programmers. I expect demand for programmers to be undiminished. That historical pattern has been super strong.
Here is some C++ code
// comments start with 2 slashes
int i = 0; // must declare var
while (i < 100) { // parens + braces
i += 1; // same as py + semicolon
if (is_bad(i)) { // parens + braces
return;
}
i += "Hello"; // error detected
// int/string types different,
// so above does not work.
// Error is flagged at edit-time:
// earlier than python, an improvement
}
Most Stanford students take 1 or 2 CS classes and keep with their chosen major. It's easy to imagine they use Python here and there as part of their work.
If you want to take CS106B, we generally recommend taking it within 6 months. It happens topics and workload in CS106B go up or down somewhat depending on who's teaching it, so you have to think a little bit which quarter is right for you. Any version of CS106B is fine for going on in the major.
We'll just mention a few courses you could take, build the picture that there are many different areas of CS you might explore. Many of these require CS106B as the pre-requisite.
A sibling to the CS major - similar intellectual domains but less focus on coding
An interdisciplinary major that uses the lenses of CS, Philosophy, Psychology and Linguistics to study systems that use symbols to represent information. In Symsys you can concentrate on AI, Neuroscience, Natural Language, Philosophical Foundations or design your own concentration.
Part of getting code to work is that you need to chase down those rare, difficult cases as well.
Below is a difficult case for the self-driving logic.

Thanks to Elyse and the section leaders! The only way this course can work is with their prodigious and generous efforts. Juliette and the section leaders are a tribe selected for technical skill and generosity - a fantastic group of people and we are lucky to have them.


In closing, I'll say that teaching this class is very satisfying endeavor - it's great to see the light in someone's eyes when the power we know in CS starts working for that student.
Best of luck with your future projects!