Model Compression for Chinese-English Neural Machine Translation
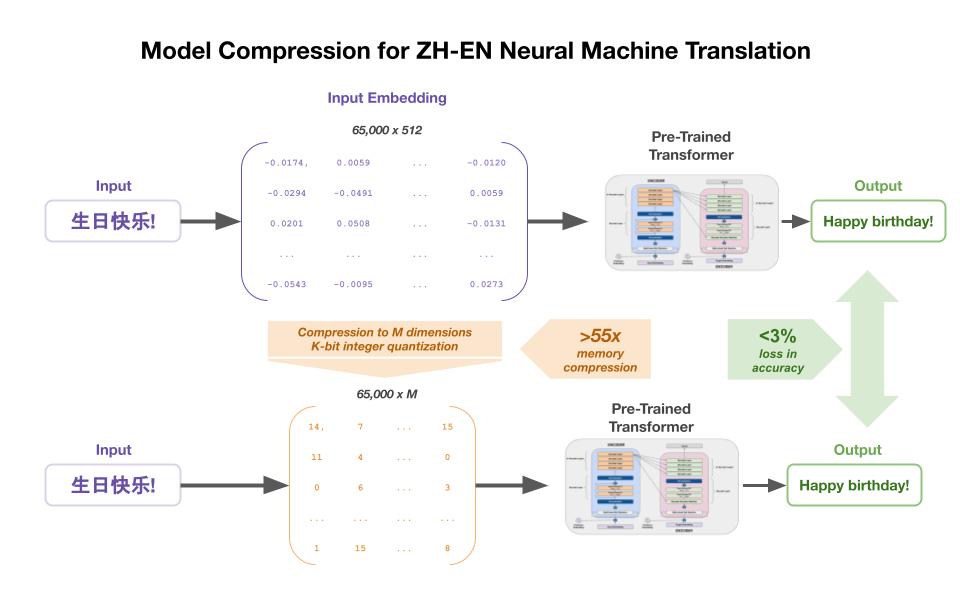
State-of-the-art neural machine translation (NMT) models require large amounts of compute and storage resources, with some of the smallest NMT models clocking in at several hundred megabytes. This large size makes it difficult to host NMT models in resource-constrained environments like edge and mobile devices, requiring that the user utilize either a stable internet connection or offline dictionary. Our goal was to compress a pre-trained NMT model as small as possible while minimizing reduction in translation accuracy. Using a pre-trained Chinese-to-English MarianMT model, Opus-MT, we tested several size reduction techniques and observed their impact on memory size, processing speed, and BLEU.
We found that the combination of embedding compression and layer quantization achieved significant levels of model compression (56x!) with only a 3% drop in our translation accuracy. The implementation has a high reward-to-effort ratio, and can be applied to any pre-trained NMT model.