iReason: Multimodal Commonsense Reasoning using Videos and Natural Language with Interpretability
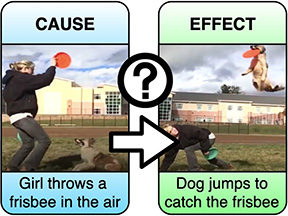
Did the dog jump because the girl threw the frisbee? Or are the two events unrelated? Ask a 10-year old this question and note how easy it is for them to answer. Why you ask? Humans have a pretty good sense of causality, which is the science of understanding the cause and effect among events. Can we impart this knowledge to AI models? Can we get them to understand the commonsense reasoning behind causal relationships that humans find so easy to reason about? Could AI models use this knowledge to get better at certain tasks? Our work seeks to answer just that! While recent models tackle the task of mining causal data from either the visual or textual modality, there does not exist widespread prevalent research that mines causal relationships by juxtaposing the visual and language modalities. Under the visual modality, images offer a rich and easy-to-process resource for us to mine causality knowledge from, but videos are denser and consist of naturally time-ordered events. Also, textual information offers details that could be implicit in videos. Enter iReason, a framework that infers commonsense knowledge using two of the most important modalities humans use to be cognizant of the world around them -- videos and language. By blending causal relationships with the input features to an existing model that performs visual cognition tasks (such as scene understanding, video captioning, video question-answering, etc.), better performance can be achieved owing to the insight causal relationships bring about. Furthermore, iReason's architecture integrates a causal rationalization module to aid the process of interpretability, error analysis and bias detection. Using a two-pronged comparative analysis comprising of language representation learning models (BERT, GPT-2) as well as current multimodal causality models, we demonstrate that iReason outperforms the state-of-the-art.