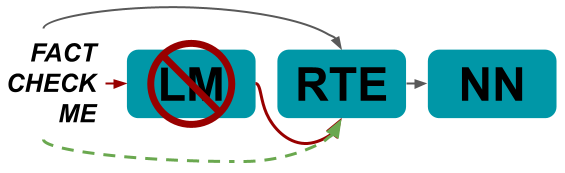
Extracting, and not extracting, knowledge from language models for fact-checking
Fact-checking is a challenging and useful classification task where a model evaluates the truthfulness of a natural-language claim. Researchers have taken a variety of approaches to building automated fact-checking systems, but recent work has introduced a paradigm that queries a language model to extract factual knowledge. We implement and evaluate several extensions to that pipeline, including alternate strategies for masking the claim and selecting the tokens that the language model predicts for masks. Evaluating these alternatives on a well-known fact-checking dataset, we find that they find that they have minimal impact on overall performance. Motivated by this finding, we construct a drastically simplified version of the pipeline - removing the language model - and find that its accuracy changes little. While its performance remains below state-of-art, these surprising results highlight difficulties in extracting knowledge from language models and introduce a new (to our knowledge) kind of entailment-based fact-checking baseline that involves no language model, corpus or knowledge base.