Improving Medical Knowledge in the Automated Chest Radiograph Report
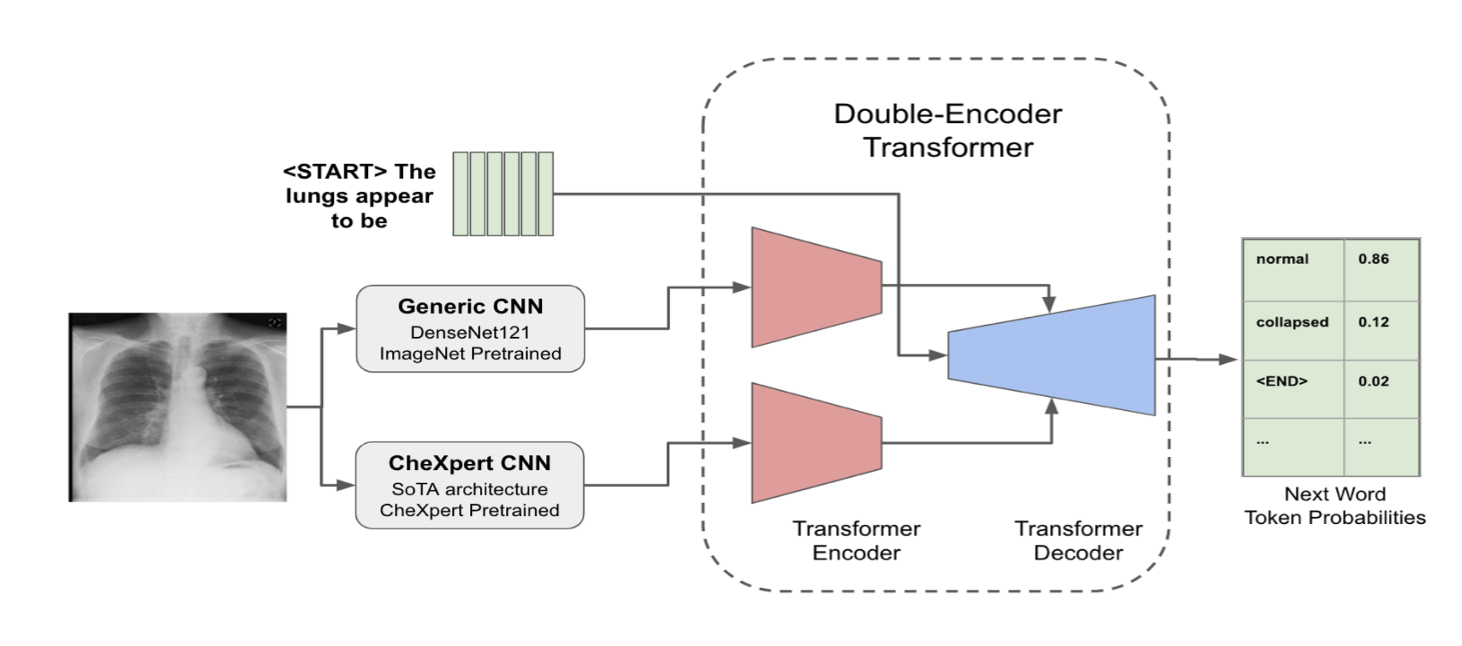
The clinical writing of unstructured reports from chest radiograph imaging is error prone, due to the lack of its standardization and repeated report writing daily, which can prove fatal. A system that generates reports can assist clinicians to reduce errors. Such a system could further be used as a training tool for medical education as well as used in the global setting to promote medical accessibility in low resource areas. Current medical report generating efforts employ the BLEU metric which was shown to score better clinically meaningless, yet grammatical, random reports. Further, state of the art methods for this task pretrain the visual extractor on Imagenet which has been shown to generalize poorly for medical domain applications. We seek to study the benefit of pretraining on a chest radiograph specific trained visual extractor. We also combine both feature extractors to study how this extra input information to the generating model can improve the semantic medical accuracy of the resulting reports. We test each model by evaluating BLEU(1-4) metrics and F1 score performance on each of 14 possible labels as defined by CheXpert for chest radiographs. We find that while the chest radiograph feature extrator model and the double feature model result in lower BLEU scores, they perform better across specific F1 scores and total F1 score. We provide evidence to suggest that the choice of Imagenet, domain specific, or combined feature extractor is dependent specifically on which medical knowledge is most important for the application. This supports the further investigation of using a combined domain specific feature extractor with an Imagenet pretrained feature extractor for medical imaging captioning tasks.