Fine-tuning of Transformer Models for High Quality Screenplay Generation
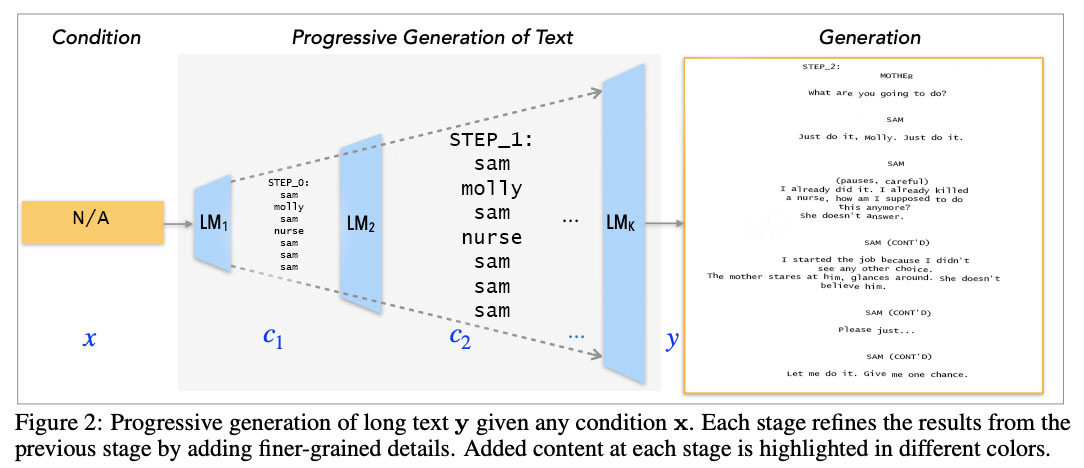
Screenplays contain semantically and structurally rich text as the average movie screenplay is thousands of words (tokens) long and contains long range dependencies of entity relations and contextual plot elements throughout. Large-scale pre-trained language models (like GPT-2) perform very well in open-domain text generation when the generated outputs are only ten to low hundreds of tokens long. This project aims to test how well current large transformer models perform at producing long, coherent texts for the task of movie screenplay generation. We compared the outputs of several different models such as GPT-2, GPT-2 finetuned for 1 epoch, GPT-2 finteuned for 3-epochs, and a recently published non-monotonic, progressive generation approach (ProGeT) to see which model and architecture could best support high quality screenplay generation. Generated screenplays were evaluated using traditional n-gram based statistical similarity scores (BLEU, MS-Jaccard, TF-IDF Distance, Frechet BERT Distance), a context embedding based similarity metric called BERTScore, and human evaluation. We found that non-monotonic generation approach performed best on a set of automated evaluation metrics, including BERTScore. Analyzing all model outputs, we see that the ProGeT model produces outputs that read most similarly to human written screenplays.