ALBERT: Domain Specific Pretraining on Alternative Social Media to Improve Hate Speech Classification
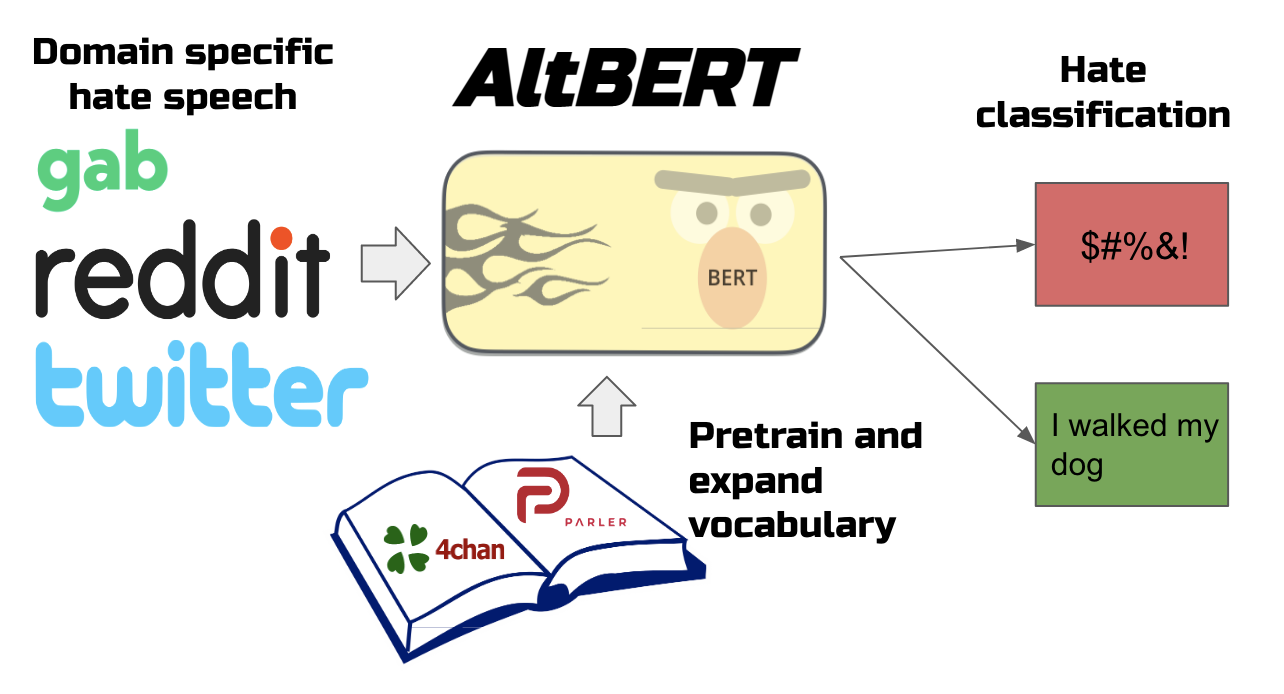
Fringe online communities like 4chan and Parler are havens of hate speech and tend to develop unique vocabularies that are challenging for hate speech classifiers to decode. These vitriolic environments normalize hateful dialogue proven to elicit real world violence, making hate speech classification an important issue for both online and offline safety. We aim to perform hate speech classification on three domain specific hate speech datasets from Twitter, Reddit, and Gab. Our aim is to improve results of hate speech classification within these fringe communities by using transfer learning by pretraining BERT models on domain specific corpora from Parler and 4chan. We build off related works by using the BERT base uncased model as our baseline. We contribute to these works by pretraining the BERT model on larger corpora and corpora of supposedly similar domains to the finetuning datasets to explore where improvements are possible. We also modified and evaluated the performance of the domain specific exBERT model. The Parler and 4chan models showed accuracy improvements over the baseline in two of the three hate speech datasets (Gab and Reddit). Importantly, improvements were observed in datasets of a similar domain to our pretraining corpora. The baseline model performed the best on the multiclass Twitter hate speech dataset, potentially illustrating domain specific pretraining's inability to classify hate speech accurately outside of its specific domain. Notably, the Parler model also achieved similar results to the baseline model for the Twitter dataset which we attribute to the size of the pretraining corpus. Our exBERT model did not show improvements to the baseline due to limitations in the existing exBERT codebase. Future works include exploring models and datasets that are able to make classification improvements without the computational requirements needed to train on large corpora.