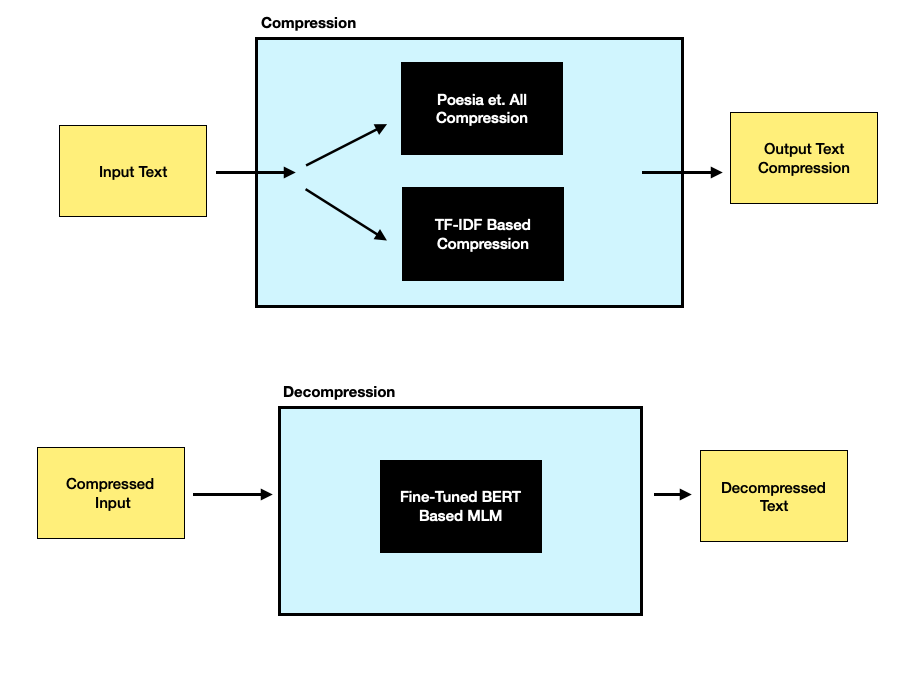
Compression is an essential tool that enables efficient transmission of information across the globe. Inspired by the Poesia et. all paper, "Pragmatic Code for Autocomplete," we built a system that applies techniques used for the autocomplete task to the task of natural language text compression. Utilizing a models' learning of contextual language understanding, we formulated a method that compresses and decompresses text in a way that achieves a greater compression rate than standard methods (i.e. gzip) with high accuracy (low information loss).
Through our experiments we explored and characterized the trade off between decompression accuracy and compression size, and framed the compression problem as a word level NLP masked language problem. We created two compression algorithms (one based on TF-IDF, the other inspired by the Poesia et. all paper) and found that a more aggressive compressor (Poesia) does the best job reducing file size, however, at the expense of decompression accuracy. We also found that larger compression vocabularies increase compression also at the expense of decompression accuracy. While none of our compressors outperform Gzip alone, they all can outperform standard compressors when applied in tandem with such compressors. When holistically evaluating our systems both objectives, we found that TF-IDF with N=300 does the best job of balancing the trade-off between decompression accuracy and compression size as it is able to reduce file size when applied with Gzip to 42.11% of the original file size while maintaining 99.81% overall compression accuracy.