Understanding Emotion Classification In Audio Data
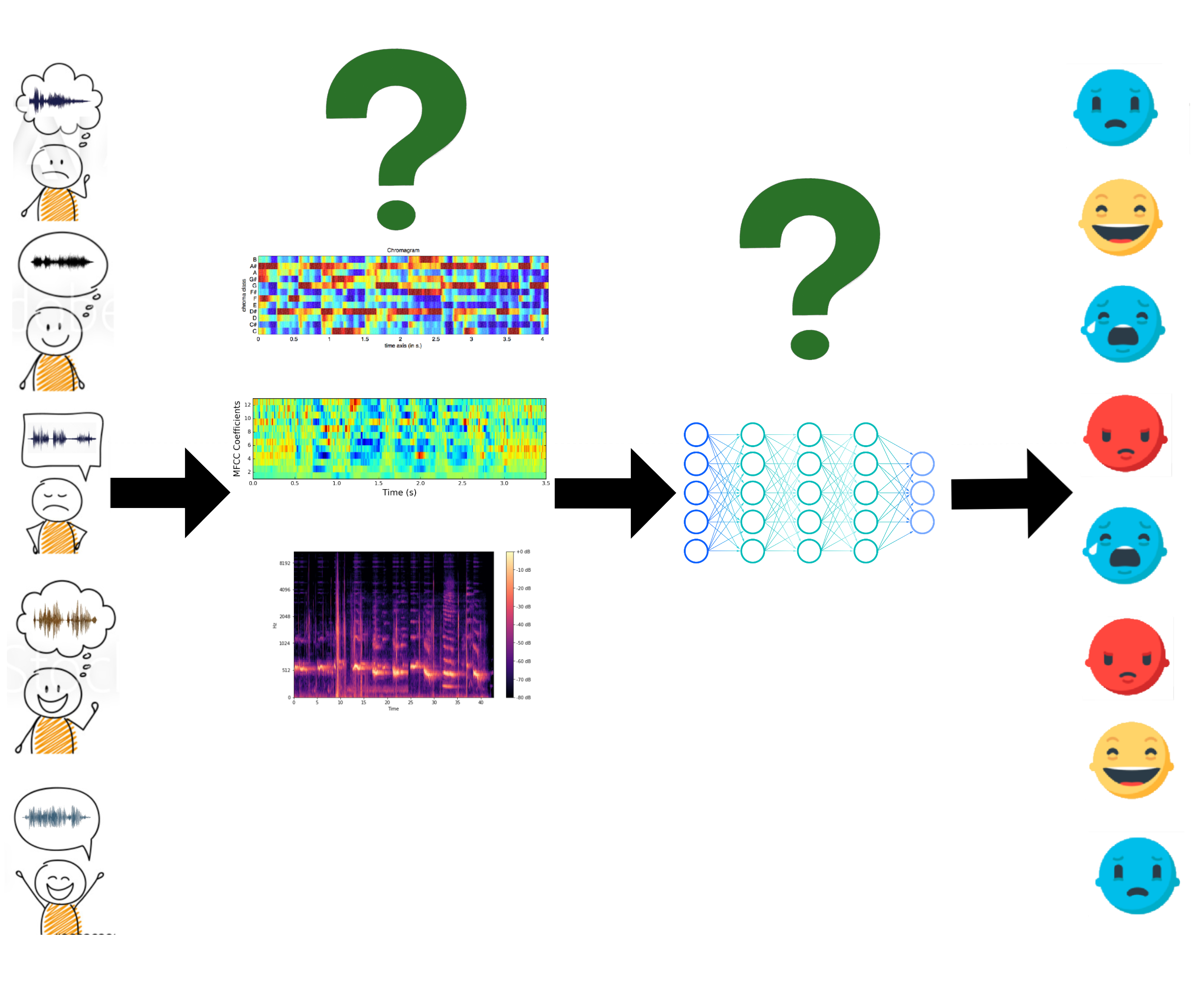
In 2020, 51% of US adults used a voice assistant and in every situation the smart device was ignorant of the users' vocal emotions. To help address this problem, our project empirically identifies the best audio representations and model architectures to use for spoken language emotion classification through extensive experimentation. We propose three new architectures which beat the existing state-of-the-art audio sentiment classification systems for our dataset (RAVDESS). We demonstrate that MFCCs and Mel spectrograms are the most important audio representations for this task and that Tonnetz representation is a decently powerful accuracy booster. Lastly, we reveal large gender disparities in classification accuracies for the most complex models.