Question Answering System Implementation Using QANet Architecture
Reading comprehension and question answering are critical natural language tasks that many modern NLP models benchmark against. Early reading comprehension models were mostly RNN based, as a result, their training and inference speed was slow. More recently, there has been a shift to use attention layers to improve the performance of those models through bidirectional attention.
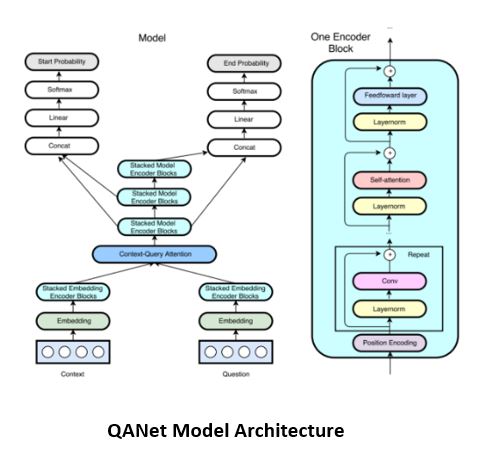
QANet's approach attempts to bring the latest NLP innovations to the Question Answering problem domain. The QANet authors introduce a novel architecture that achieves both fast and accurate performance. Drawing inspiration from the Transformer paper, the QANet model encoder consists exclusively of convolution and self-attention. The feed-forward nature of this architecture drastically improves training and inference performance, while maintaining good accuracy.
In my project, I implemented the baseline (unaugmented) QANet model from scratch and evaluated it on the SQuAD 1.1 dataset. My analysis of the QANet performance has showed that, overall, the model still makes errors that are common to question answering deep learning models. For example, it still struggles with inference, bridging, analogy, as well as logical analogy. Also, I observed that the model tends to get confused by multiple prolific context entries, which causes it to discard relevant context information while focusing on the phrases that are most similar in structure. Finally, QANet also tends to fail when there seem to be more than one viable answer to questions. Possible ways to alleviate those issues could be to add more self-attention heads to the QANet architecture while decreasing the number of encoder blocks. I believe, that could help the model better learn global dependencies and could also improve the model's ability to perform logical reasoning. Moreover, using pre-trained contextual embeddings, or adding other features to the input vectors (e.g., named entity types) might also improve the model's performance.