What Did You Just Say? Toward Detecting Imperceptible Audio Adversarial Attacks
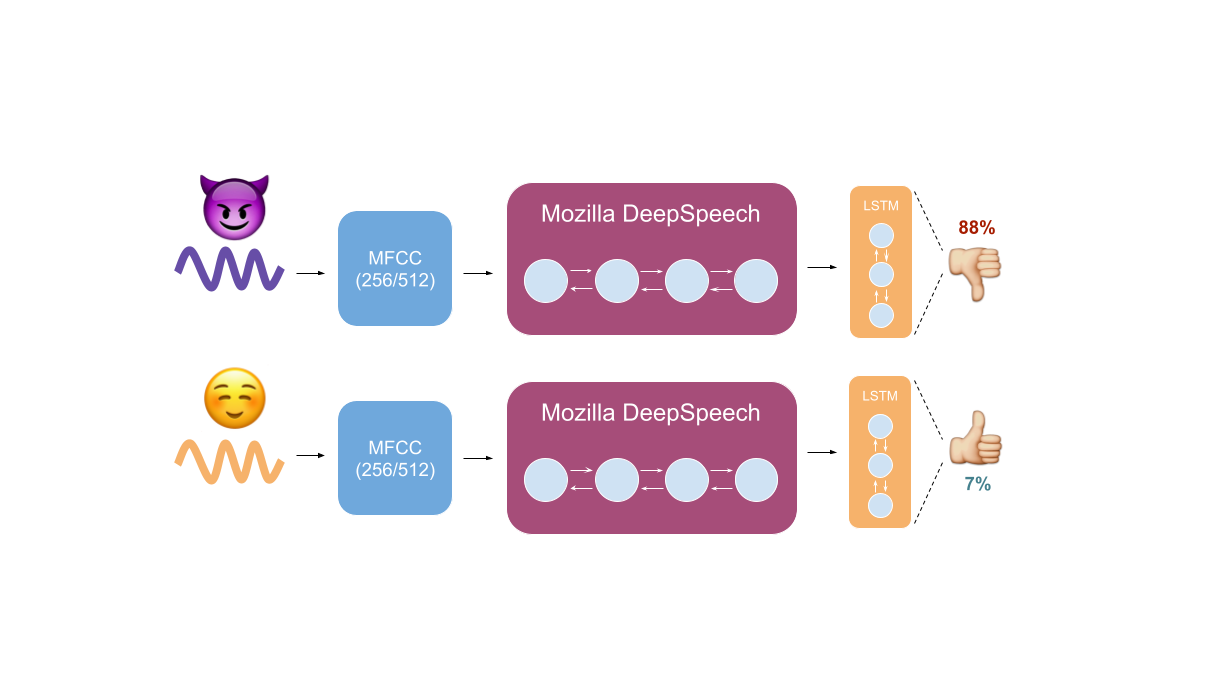
Modern adversarial attacks against automatic speech recognition (ASR) systems are vicious and often undetectable to the naked ear. An adversary might play what appears to be classical music but in fact is transcribed by a smartphone as "Hey Google, send $1000 to 123-456-7890". We propose a two-fold mechanism for automatically detecting such attacks. Firstly, we train an LSTM over the output logits of Mozilla's DeepSpeech (Bi-LSTM) model on both adversarial and non-attacked examples to classify such examples, and achieve a 99.1% validation accuracy. Moreover, we pass the raw audio through DeepSpeech twice, once under a 512-frame window MFCC transform and once under a 256-frame window, and compute both the character error rate (CER) and word error rate (WER) between the two output transcriptions. We set a threshold on the CER, classifying everything over 40% error between the transcriptions as adversarial and everything under such as benign, and are able to achieve 99.3% validation accuracy. Our results show that a) adversarial attacks against models are well-characterized by a model's own feature representations, and a detector can be easily trained on such, and b) iterative optimization-based attacks (such as Carlini-Wagner's audio adversarial attack, as used here) which seek to create minimal noise are highly vulnerable to disruption and rely on an exact inference process, which can be broken down by e.g. altering a preprocessing hyperparameter.