I Have(n't) Read And Agree To The Terms Of Service
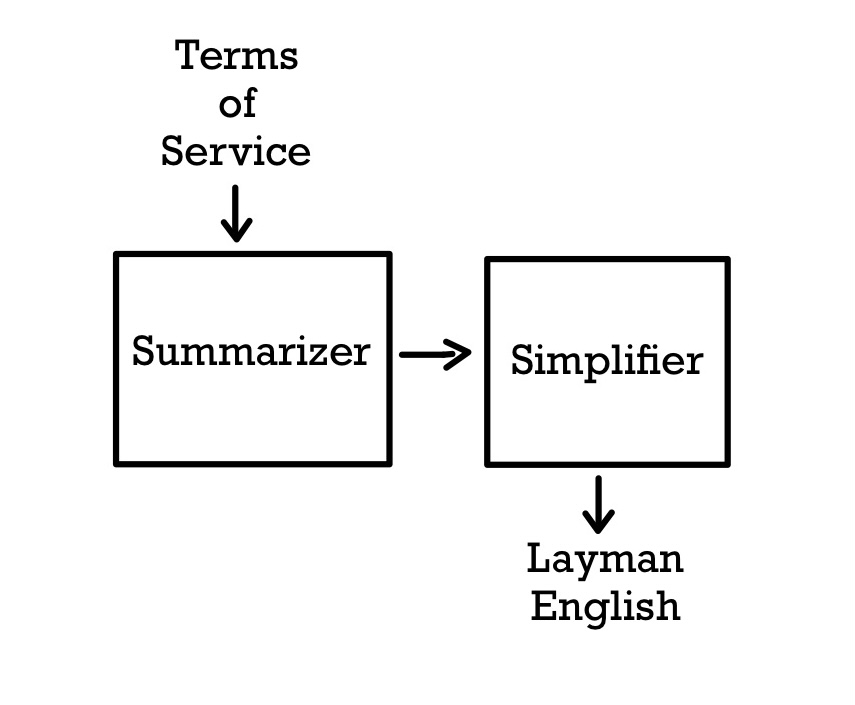
People interact with legalese on a daily basis in the form of Terms of Service, Cookie Policies, and other agreements that (for the most part) are mindlessly accepted. In order to give people transparency into the services they use, we aim to develop an abstractive summarizer which simplifies these legal documents. Leveraging an existing dataset of human interpretations of Terms of Service, known as TOS;DR, we developed a two-step pipeline involving extractive summarization followed by text simplification. We use state-of-the-art, transformer-based methods for both steps of this pipeline. Specifically, for extractive summarization we use the CNN/DM BertExt model presented by Liu et al. For text simplification, we used the ACCESS model presented by Martin et al. We first established a baseline of our extractive summarizer performance via ROUGE, our text simplifier performance via SARI and FKGL, and the performance of our pipeline end-to-end via ROUGE. These baselines were established using the pretrained models provided by the authors of these papers. We then employed a variety of data cleaning and data augmentation techniques, as well as model finetuning to improve upon these baseline results. We demonstrate that these techniques result in an improvement in model performance on legalese, both when these models are used in isolation, as well as when these models are used end-to-end. While we did improve on our baseline results, our qualtiative analysis demonstrates that these models are not near the level required for a production-level system, and our results demonstrate shortcomings in the adaptability of these large transformers when pretrained on specific, parallel datasets.