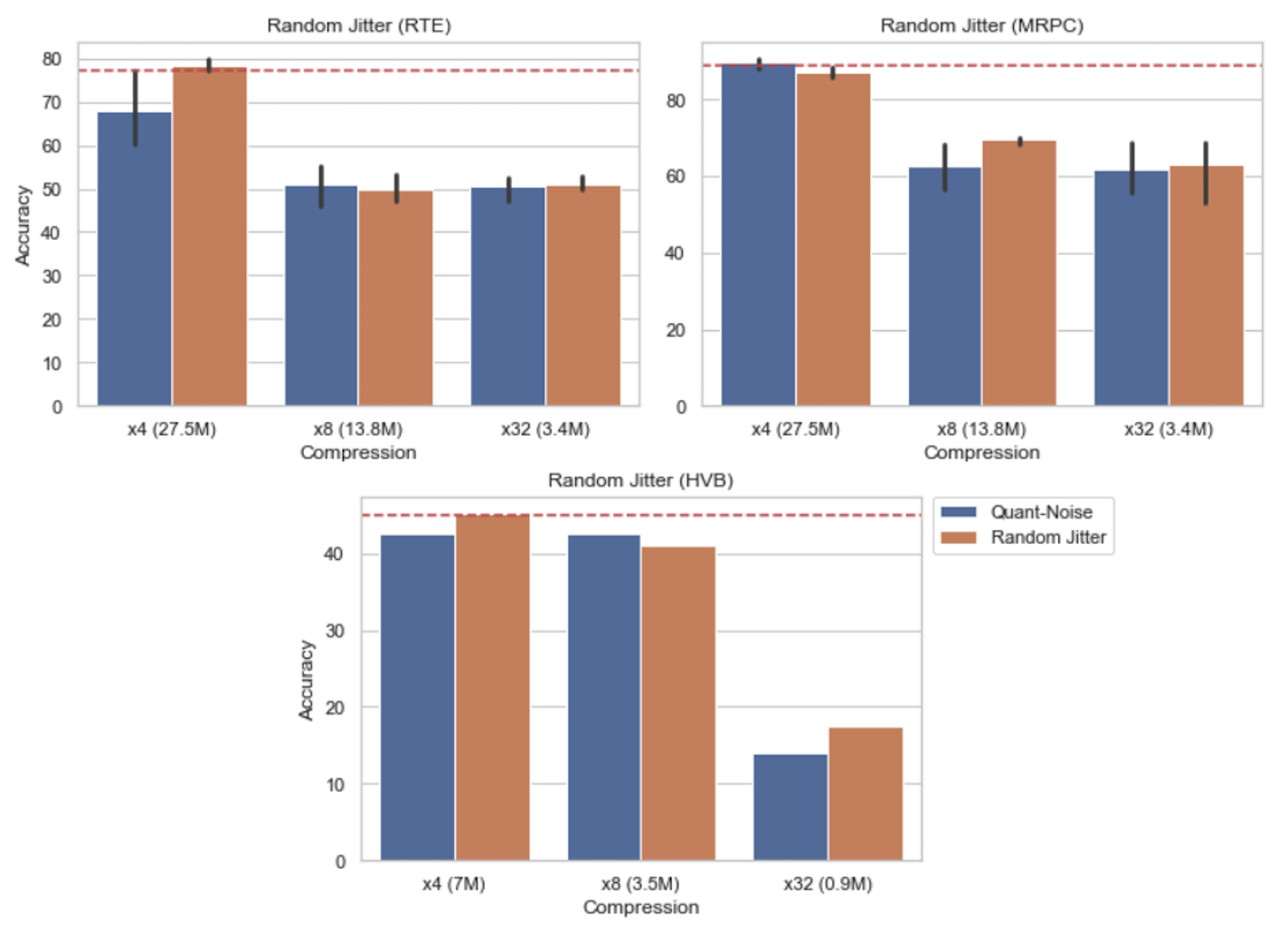
Memory and compute constraints associated with deploying AI models on the edge have motivated the development of methods that reduce larger models into compact forms. One such method, known as scalar quantization, does so by representing a neural network with fewer bits. For instance, instead of using 32 bits for each parameter, we can represent them with 8 or fewer. However, naively applying quantization to a neural network after training often leads to severe performance regressions. To address this, Google published a method called "Quantization Aware Training," which applies simulated training-time quantization for the model to learn robustness to inference-time quantization. One key drawback of this approach is that quantization functions induce biased gradient flow through the network during backpropagation, thus preventing the network from best fitting to the learning task at hand. Facebook AI Research (FAIR) addressed this issue by proposing "Quant-Noise," in which they apply simulated quantization to a fixed proportion, called the "noise rate," of parameters during training rather than all of them. FAIR's methods set a new state-of-the-art for quantization. Our method, "Quant-Noisier," builds upon their technique by using a variable noise rate instead of a fixed one, which we term "second-order noise." We craft four candidate functions to vary noise rate during training and evaluate the variants with 129 experiments-3 datasets, 3 quantization schemes, several methods, and 3 random seeds for most trials. Quant-Noisier with a variant stochastic second-order noise outperforms Quant-Noise on two out of three quantization schemes for all three tested datasets. Moreover, on two of the datasets, our method at 4x compression matches or exceeds performance of even the uncompressed model. We hope that our novel compression approach improves the tractability of model training and inference for a wide range embedded computing applications.