Multilingual CheXbert: Radiology Report Labeling in Spanish
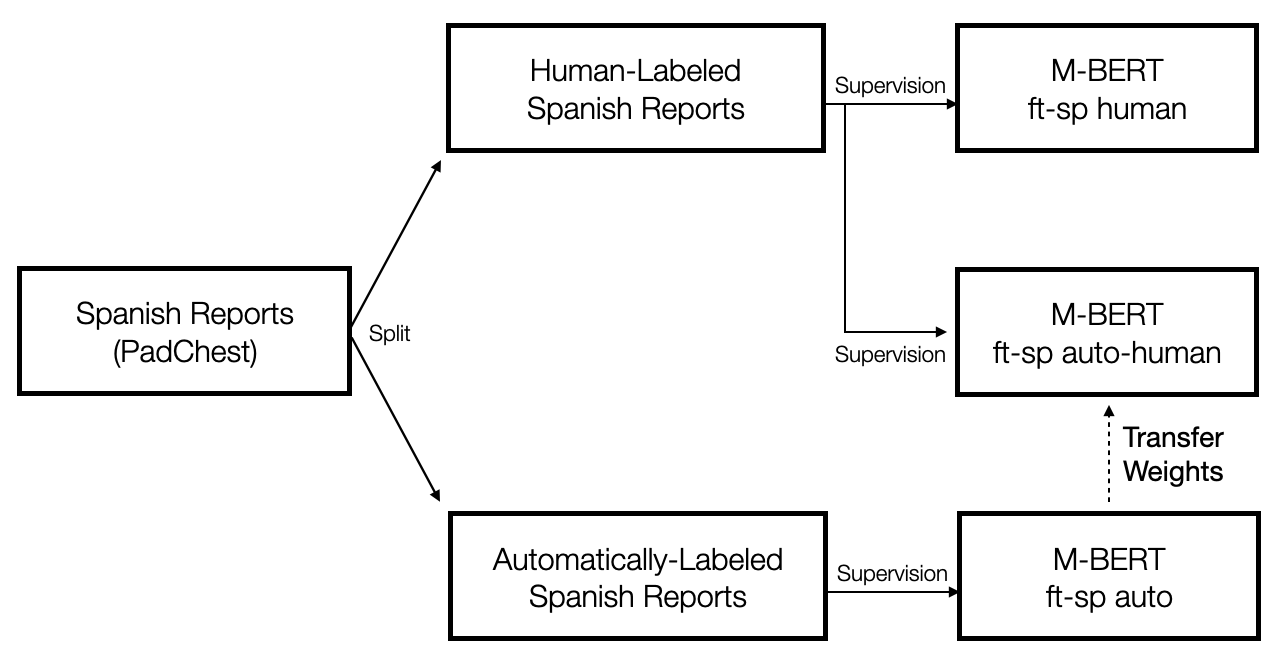
Automatic label extraction from free-text radiology reports enables efficient and large-scale training of natural language processing models for the medical setting.The current state-of-the-art label-extraction model, CheXbert, has been shown to work well on English-language radiology reports, but has not yet been tested in the multilingual setting. In this work, we explore how well Multilingual BERT performs on Spanish-language radiology reports. We find that regardless of whether the model is finetuned on English reports or Spanish reports, Multilingual BERT offers no real performance gains over English BERT when evaluating on Spanish-language reports. Furthermore, we show that while finetuning on human-labeled reports is better than finetuning on automatically-labeled reports, finetuning first on automatically-labeled reports and then further finetuning on human-labeled reports offers the best results.