Fake News Detection and Classification with Multimodal Learning
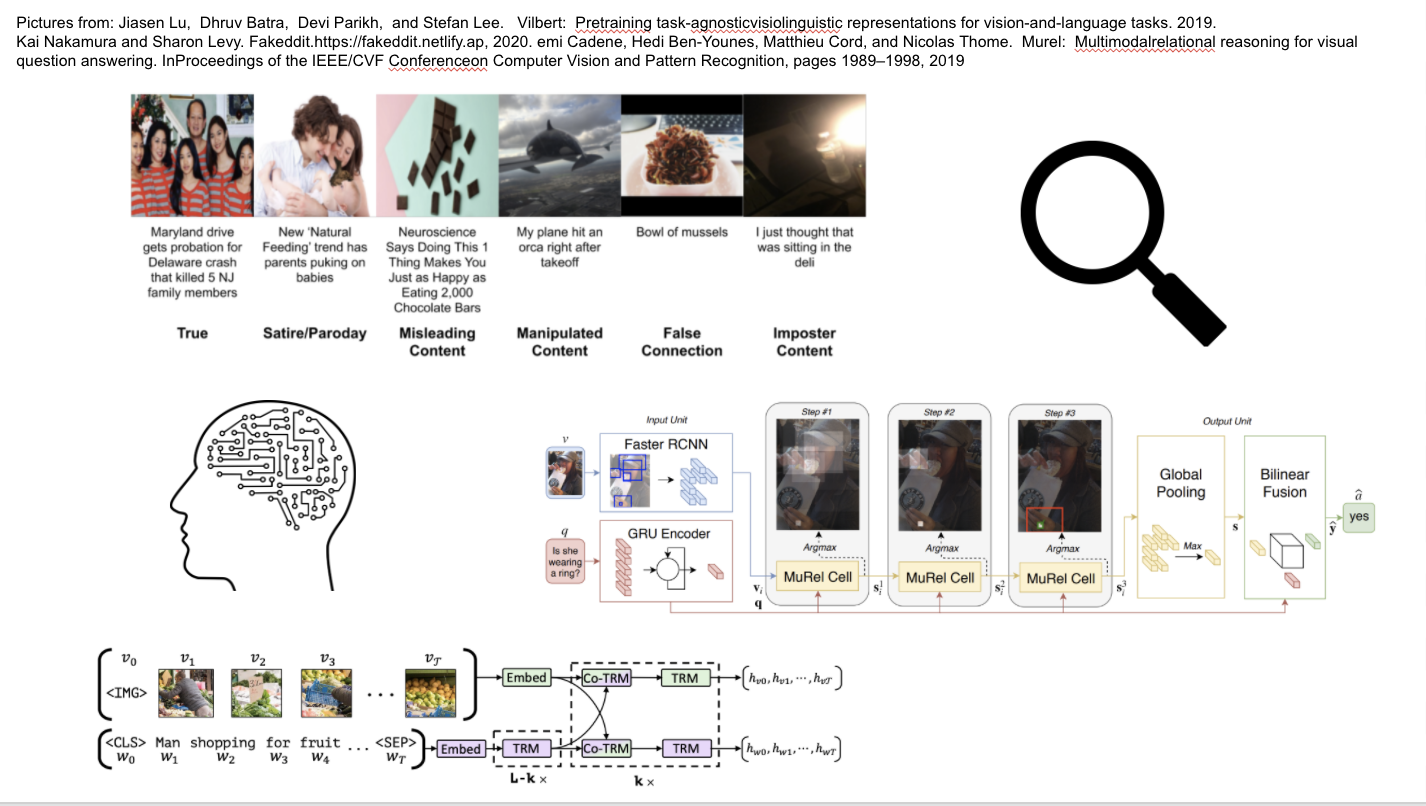
In recent years, the prevalence of fake news has increased significantly with the rapid progress in digitization and the rise of social media. It has harmed our society greatly by spreading misinformation and escalating social issues. To combat the spread of misinformation in multiple modalities, we experimented with various new multimodal machine learning models and mutimodal feature fusion techniques to improve the current benchmark on fake news detection with Fakeddit dataset. Although the baseline results from the dataset authors are already quite impressive, we believe more sophisticated visual/language feature fusion strategies and multimodal co-attention learning architecture could capture more semantic interactions/associations between visual and language features that come in pairs in fake news. The understanding of visuals should be conditioned on the text, and vice versa. This belief motivated us to explore several new approaches to this problem including mBert, MuRel, as well as ViLBERT after implementing the baseline model as a benchmark. Our experiments demonstrate the importance of learning associations between the two modalities and aligning visual and text signals in the fake news detection task. Also, learning visually-grounded language understanding has also been proven to be transferable and pretrainable among different vision-and-language tasks.