How Low Can You Go? A Case Study in Extremely Low-Resource NMT
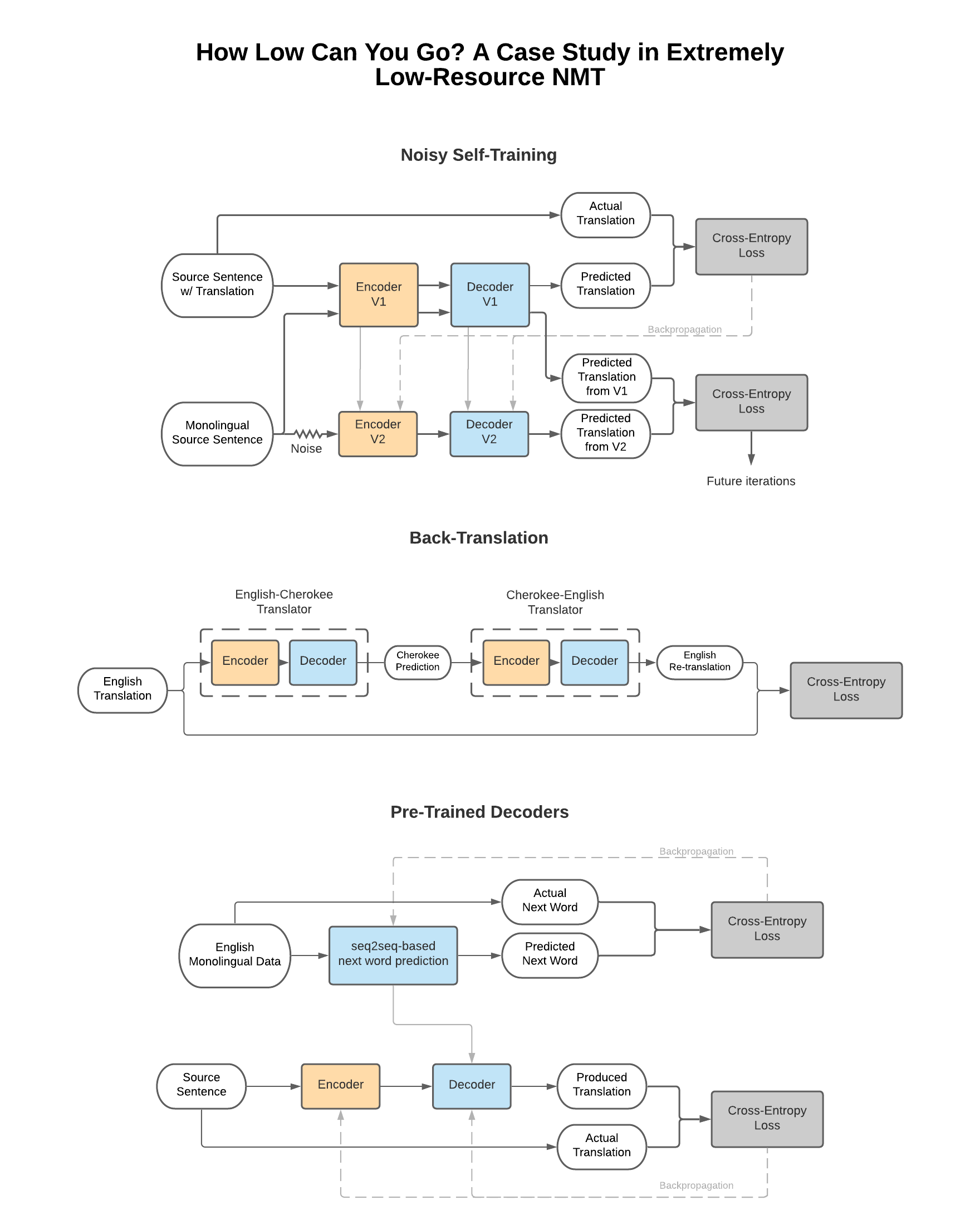
Neural Machine Translation (NMT) has improved dramatically in the past decade, with many NMT systems for high-resource languages approaching human-quality translations. However, many of the world's languages are low-resource, with very little digitized parallel data available to train NMT models for them. Although there have been many advancements in developing techniques for low-resource NMT, many languages still have orders of magnitude less data than those used in the associated studies. One such extremely low-resource language is Cherokee, which has less than 15,000 parallel Cherokee-English sentences available. We present a case-study that evaluates the efficacy of common low-resource NMT techniques on Cherokee-English (ChrEn) translation. We analyze the performance of data augmentation, noisy self-training, back-translation, aggressive word dropout, pre-trained word embeddings, pre-trained decoders, mT5, and additional LSTM layers on improving a ChrEn NMT system. We find that pre-training the decoder with 100,000 monolingual English Sentences and back-translation using 5,000 English sentences offer a 0.9 and 0.8 BLEU score improvement over the baseline, respectively, while noisy self-training and aggressive word dropout provide inconsistent benefits in this extremely low-resource setting.