Adversarial Approaches to Debiasing Word Embeddings
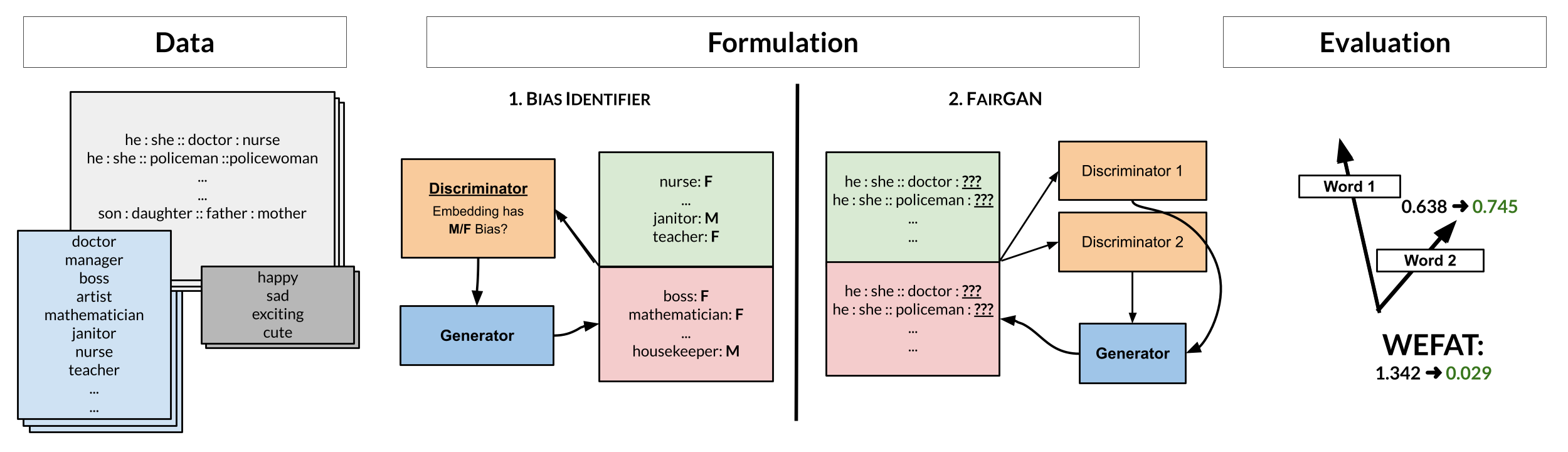
In recent years, word embeddings have been ever more important in the world of natural language processing: techniques such as GloVe and Word2Vec have successfully mapped words to n-dimensional vectors that store precise semantic details and improve the quality of translation and generative language models. Since word embeddings are trained on human text, however, they also reflect unwanted gender and racial bias over decades of societal history. In this work, we propose that bias can be mitigated through the use of Generative Adversarial Networks. We experiment with two different problem formulations. First, we experiment with a discriminator that attempts to identify the gender bias of a vector, paired with a generator that minimizes the discriminator's performance on the task. Second, we experiment with a discriminator attempting to complete word analogies and identify the gender bias of the analogy, paired with a generator that only minimizes the discriminator's ability to identify the gender bias. Preliminary results on the WEAT scoring system show that both methods were successful in eliminating bias on commonly-used job words; qualitative analysis on similar words also show that racially or gender charged synonyms were considered less relevant to the debiased vector.