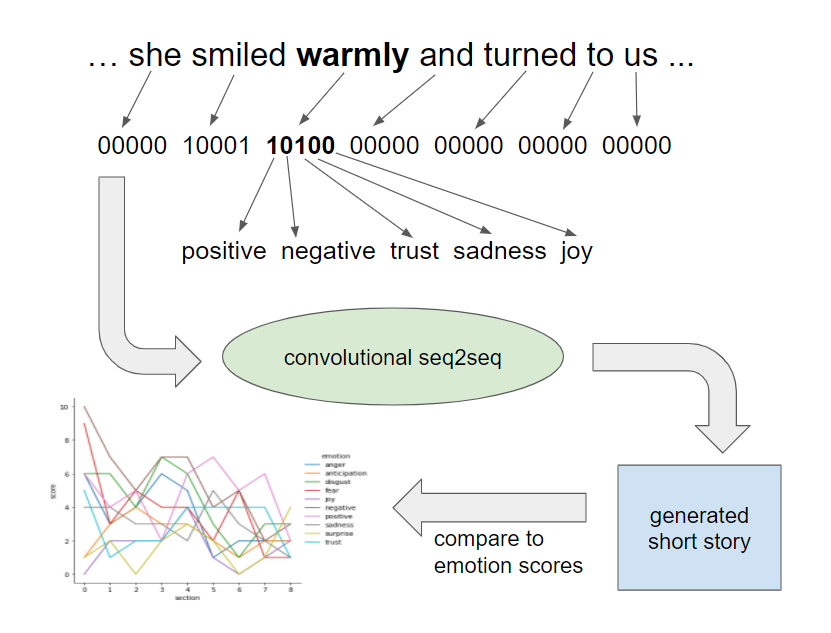
We introduce the creation and use of full-text, distributed feature maps as the basis for the hierarchical generation of long-form text. The problem of story generation, a challenge that consists of generating narratively-coherent passages of text about a particular topic, can be described as one of the most difficult challenges currently posed in text generation, as stories require long-range dependencies, creativity, and a high-level plot. Previous efforts note that story generation often fails to meet one or more of these requirements; generated stories are frequently repetitive, and typically lack any kind of a broader arc. We find that the use of automatically-generated "emotion maps" as a basis for hierarchical generation achieve perplexity scores comparable to previous efforts, despite using a numerical input rather than a textual one. Additionally, we introduce a new story generation dataset, consisting of 100,000 one thousand word stories, each paired with a series of tags which contain genre, character, and other feature information. We demonstrate that use of fully quantifiable feature maps as a conditional basis for generation achieves results comparable to the state of the art on multiple datasets. We also introduce a method for quantifying feature map/story relationship, and use this metric to show that the feature maps have a limited, but extant relationship to the generated text. Future use of quantitative analysis in hierarchical generation will aid researchers in effectively constructing and using first-step prompts for story generation.