Exploring the Limits of the Wake-Sleep Algorithm on a Low-Resource Language
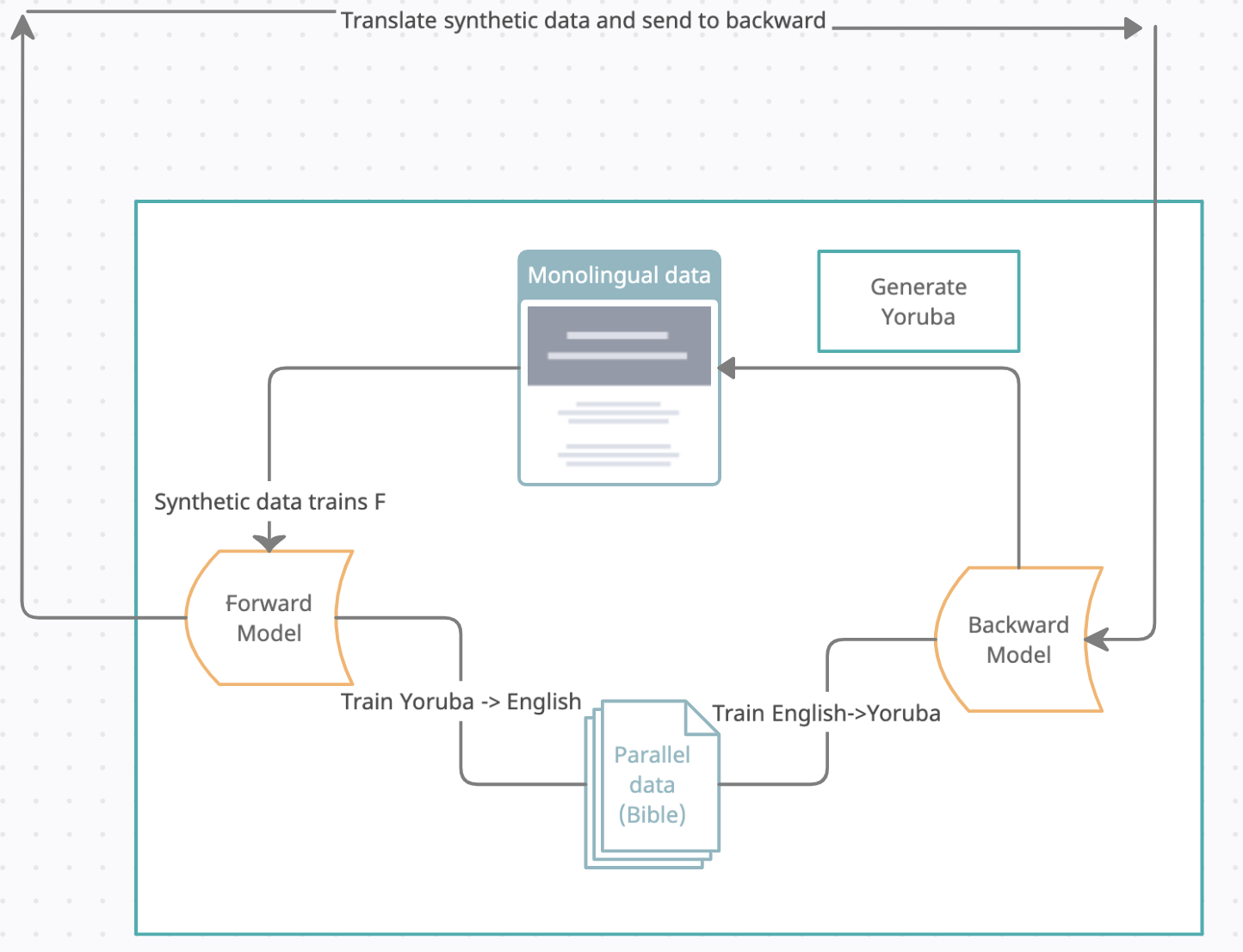
Machine Translation (MT) remains an open sub-problem in Natural Language Processing (NLP). Recently developed systems have achieved impressive, near-human performances on certain languages, but these systems are heavily dependent on large parallel corpora in the source and target languages. Thus, this approach is impractical for languages with sparse bodies of text; the real challenge lies in creating machine translation systems that are able to provide high quality, syntactically-correct translations with small amounts of parallel corpora. This work aims to utilize the wake-sleep back-translation algorithm introduced by Cotterell and Kreutzer \cite{Cotterell} in order to generate synthetic training data that will then be used on OpenNMT's pre-built models in order to achieve high-quality Yoruba-English translations. We also explore the effectiveness of the wake-sleep algorithm when used in-conjunction with in-domain data (in domain meaning data of a similar--or very closely related--subject as the original training data) versus out-of-domain-data (data not necessarily related in topic to the training data). We examine the performance differences between a smaller, in-domain dataset and a larger, less topical out-of-domain dataset and compare those results to our baseline. We find that performing the wake sleep algorithm on a small, in-domain dataset leads to a decrease in BLEU score of about 5 points when compared to the baseline model (14.47). Training on an out-of-domain dataset leads to a 6 point decrease in the BLEU when compared to the baseline.