Identify Semantically Similar Queries in Virtual Assistant Dialogues
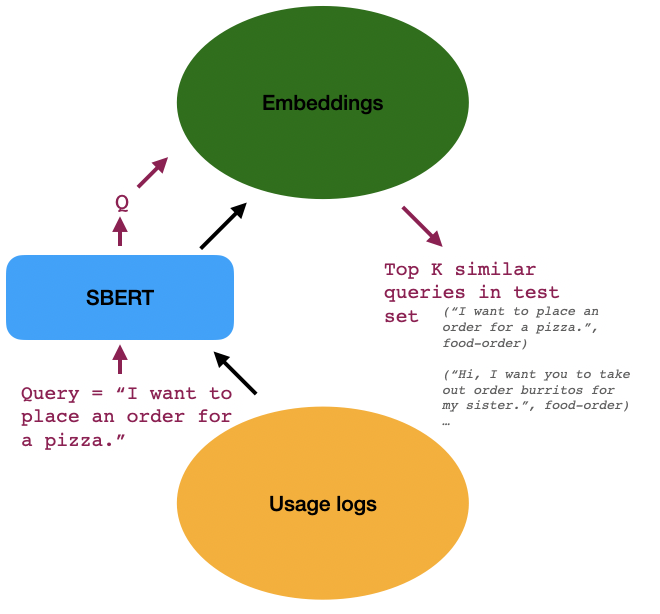
Currently for production voice assistants, it's hard to accurately understand feature usages from usage logs, because if a query is not parsed with the correct intent in the existing natural language understanding system, then it's unlikely to be counted towards the correct feature usage downstream. We translate this problem into a paraphrase mining problem: given an input example query, can we find other similar queries asking for the same feature in the raw text dialogue corpus? We leverage Sentence-BERT (SBERT), a finetuned Bert variant that can produce meaningful sentence embeddings useful in common semantic textual similarity tasks, to produce embeddings for raw text user queries. Then we can find similar user queries directly by comparing cosine similarity of embeddings. Inspired by the fact that entities in a sentence are often strong indicators of its semantic meaning, we tried improving SBERT performance by emphasizing entities in input texts leveraging named entity recognition techniques. In our experiments, we actually found that simple preprocessing of input texts by prepending entity tags strings in front of entities can visibly improve model performance in identifying similar feature queries.