Improving QA System Out of Domain Performance Using Data Augmentation
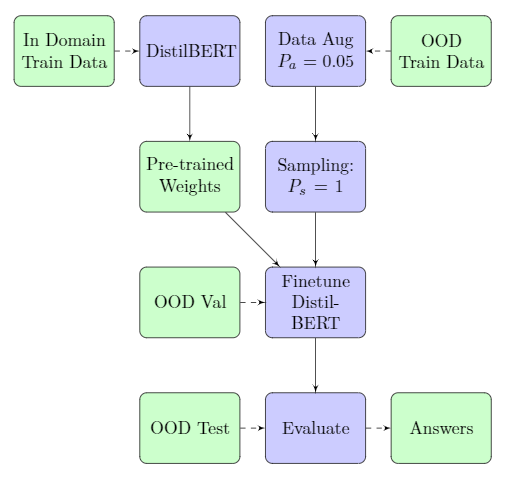
In recent years question and answering (QA) systems have become widely used in many modern technology applications, such as search engine querying and virtual assistants. However, despite recent advances in QA modeling, these systems still struggle to generalize to a specific domain without specialized training data and information about that domain's distribution. For this reason, we investigated the effectiveness of different data augmentation and sampling techniques to improve the robustness of the pre-trained DistilBERT QA system on out of domain data. We trained the DistilBERT model on the in domain data and then experimented with fine-tuning using augmented versions of the out of domain data. To generate the additional data-points we performed random word deletion, synonym replacement, and random swapping. We found that all the fine-tuned models performed better than the baseline model. Additionally, we found that our optimal synonym replacement model performed the best on the out of domain test set, and that the combination model of synonym replacement and deletion also led to increased performance over the baseline. Overall, we conclude that data augmentation does increase the ability of our question answering system to generalize to out of domain data and suggest that future work could look further into applying combinations of these data augmentation techniques.