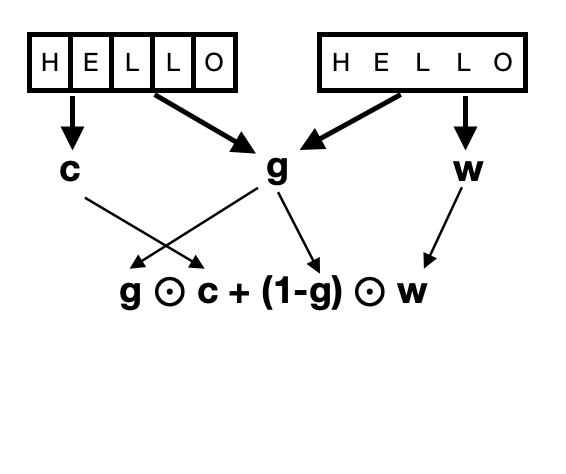
The purpose of this project is to implement an embedding mechanism on top of the BiDaf model that serves as a compromise between word-level embeddings and character-based embeddings that can compete with a simple concatenation of word and character level embeddings. In particular, the mechanism is what is called a fine-grained gating method, in which, given a character level embedding $c$ and a word-level embedding $w$, a parameter $g$ is learned such that final embedding of a given word is $g \odot c + (1-g) \odot w$, where $\odot$ represents termwise multiplication. After various experiments varying the methods by which the parameter $g$ is learned, results ultimately show that none of the fine-tuned gating methods perform better than mere concatenation of the word and character embeddings.