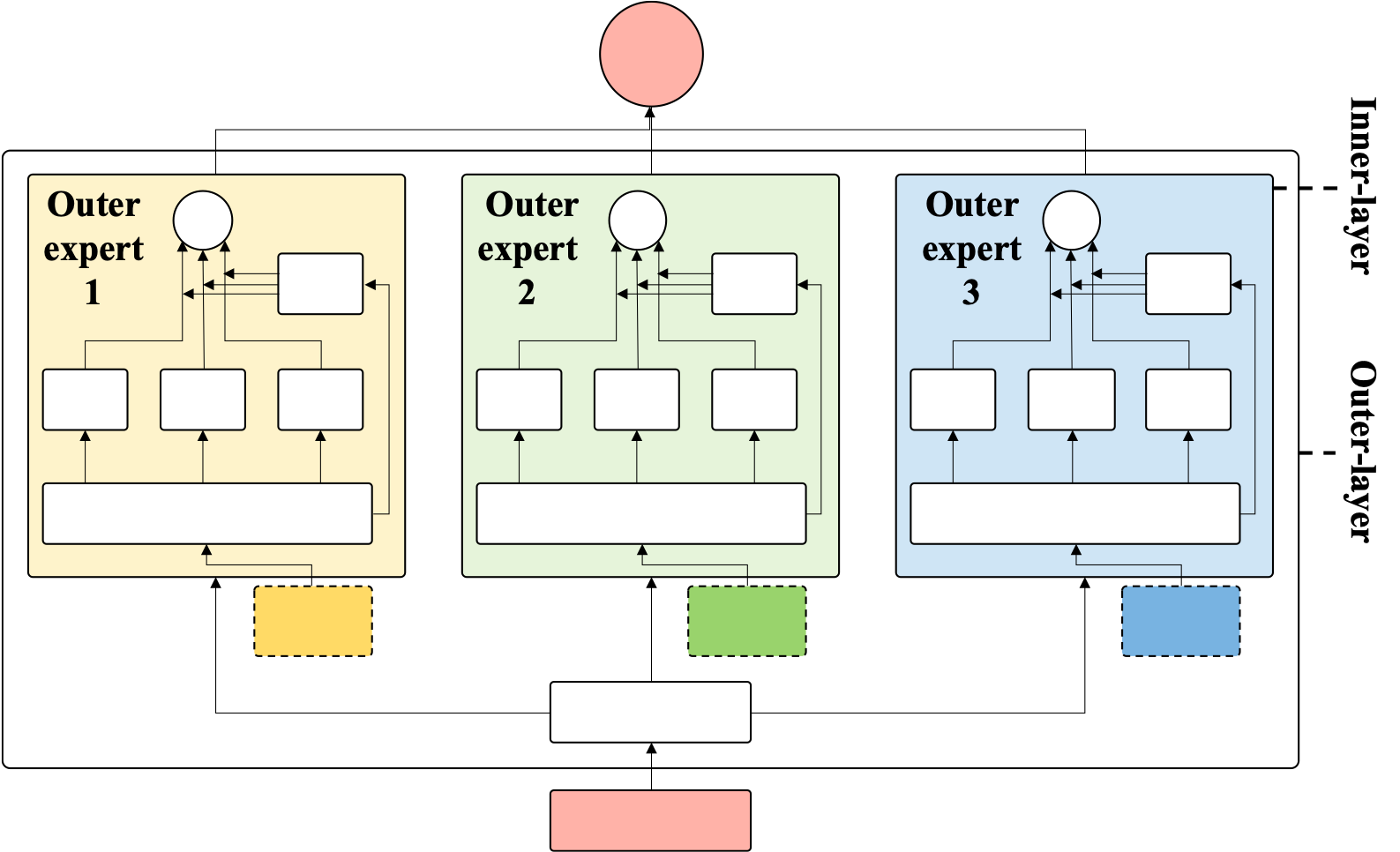
DistiIBERT Augmented with Mixture of Local and Global Experts
Few-shot systems are valuable because they enable precise predictions using small amounts of expensive training data, making them particularly cost-efficient. In this paper, we explore a technique to improve the few-shot question answering capabilities of a pre-trained language model. We adjust a pre-trained DistilBERT model such that it leverages datasets with large amounts of training data to achieve higher question-answering performance on datasets with very small amounts of available training data using a novel inner- and outer-layer Mixture of Experts (MoE) approach.
Practically, we first connect pre-trained DistilBERT models and an MoE layer in sequence (inner-layer) and train them on all high-availability data and on a single dataset with low data availability. Then we use several of these DistilBERT-MoE models in parallel to predict observations from multiple datasets with low data availability (outer-layer). We find that the noise reduction achieved by training designated DistilBERT-MoE models for different datasets with low data availability yields greater prediction benefits than the (possibly) increased transfer learning effects achieved by training a single DistilBERT-MoE model on all high- and low-availability datasets together. Both our inner-outer-MoE method and a single DistilBERT-MoE model outperform the baseline provided by a finetuned DistilBERT model, suggesting that the mixture of experts approach is a fruitful venue to enabling robust predictions in contexts with few training examples.