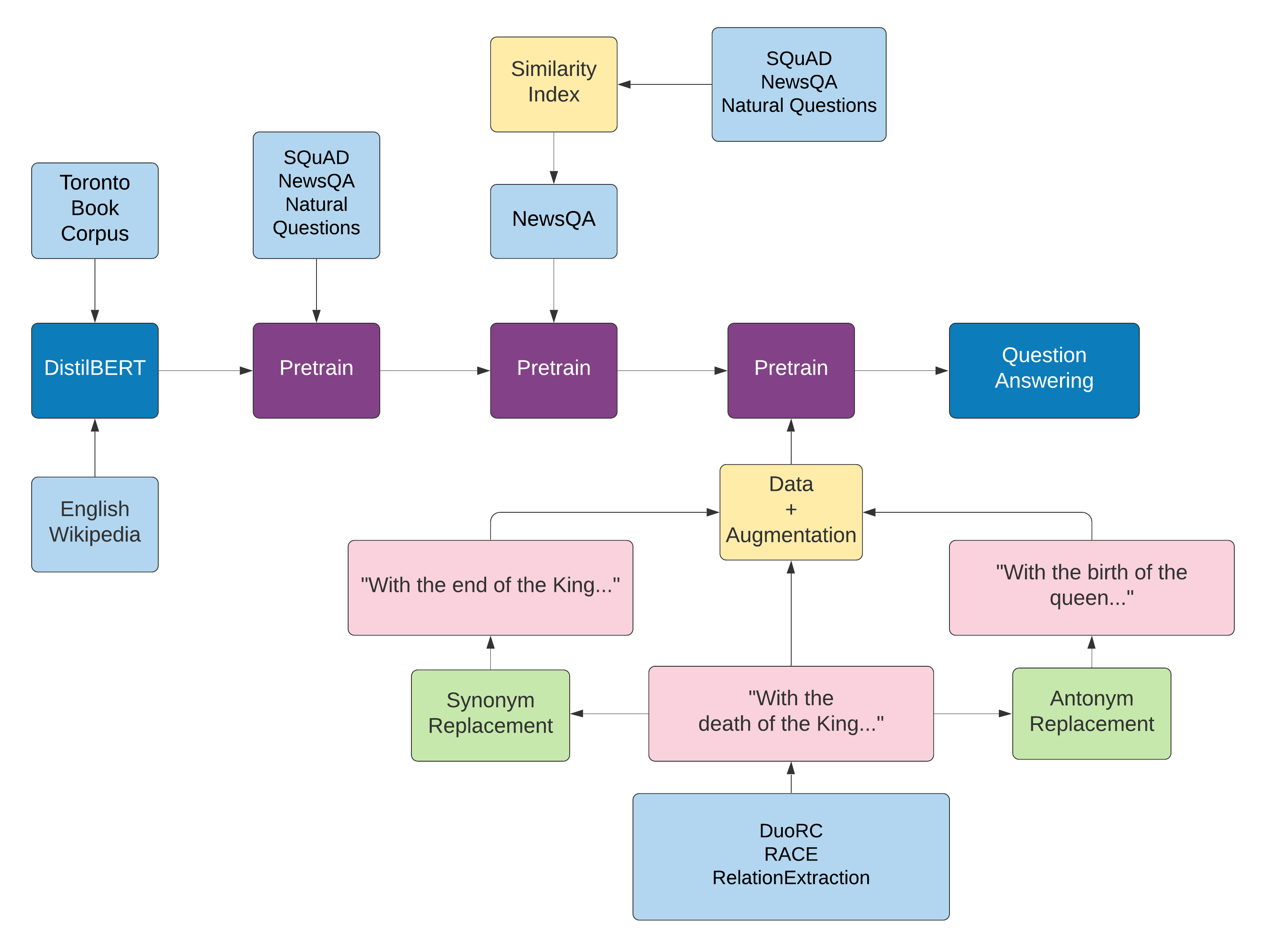
In this project, we worked on improving the robustness of DistilBERT to out-of-distribution data in a question answering task by employing multi-phase continued pre-training and data augmentation. The in-domain datasets included SQuAD, NewsQA, and Natural Questions, while the out-of-domain datasets included DuoRC, RACE, and RelationExtraction.
For multi-phase pre-training, we first analyzed the domain similarity between the in-domain and out-of-domain datasets and found NewsQA to be the most similar dataset to the downstream task of question answering based on examples from DuoRC, RACE, and RelationExtraction datasets. We then first trained the model on in-domain datasets and called it the second-phase continued pre-training. After using NewsQA for third-phase continued pre-training, we used data augmented with synonym and antonym replacement to perform the fourth-phase pre-training. The best model achieved performance, as evaluated by EM/F1 score, of 35.60/51.23 on validation datasets and 40.39/59.42 on test datasets in comparison to the baseline of 29.06/46.14 on validation datasets.