Examining the Effectiveness of a Mixture of Experts Model with Static Fine-tuned Experts on QA Robustness
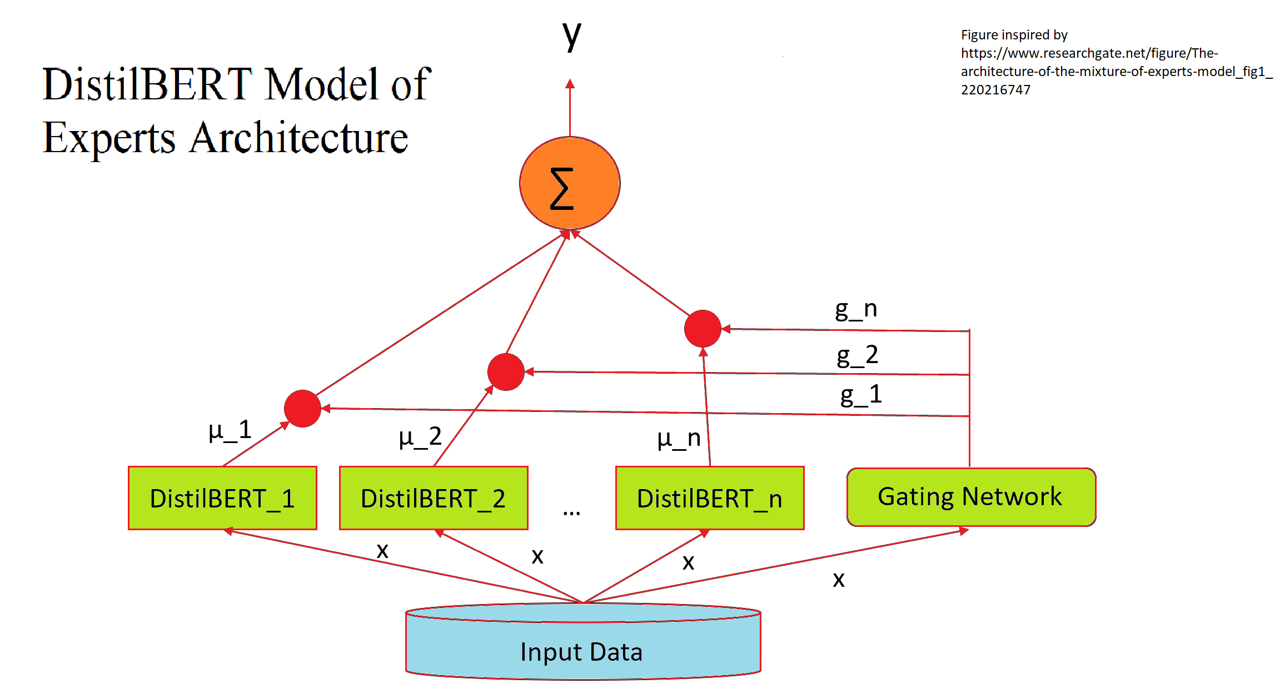
While much progress has been made in recent years on modeling and solving natural language understanding problems, these models still struggle to understand certain aspects of human language. One of the most difficult areas for current models is generalization. While humans can easily generalize beyond a training data set, computers often have difficulty developing non-superficial correlations beyond the provided data. In this project, we tackled this concept of computer generalization through the development of a robust question answering (QA) system that is able to generalize answers to questions from out-of-domain (OOD) input. Here, we applied a modified Mixture of Experts (MoE) model, where gating and expert training are handled seperately, over the 6 datasets in order to create robustness through specialization of the various expert models. We also applied few-sample fine-tuning to large and small components of the model to try to better account and generalize for cases where there is little data. Ultimately, from the results of the model, we observed that this modified MoE architecture has several limitations through its expert and training method and was unable to improve significantly on the baseline of the model. In addition, we also observed that the few-sample fine-tuning techniques greatly improved the performance of the small, out-of-domain expert but barely improved, and sometimes harmed, models with a larger dataset. As a whole, this paper illustrates the potential limitations of applying a simple MoE model and few-sample fine-tuning to the complex task of generalization and may suggest the implementation of more advanced structures and techniques are necessary for strong performance.