Efficiency of Dynamic Coattention with Character Level Embeddings
Question answering has long been a difficult task for computers to perform well at, as it requires a deep understanding of language and nuance. However, recent developments in neural networks have yielded significant strides in how well computers are able to answer abstract questions; concepts like dynamic coattention and character level embeddings have helped machines with abstract tasks like reading comprehension. Despite these strides, training models utilizing these techniques remains cumbersome and exceedingly time consuming.
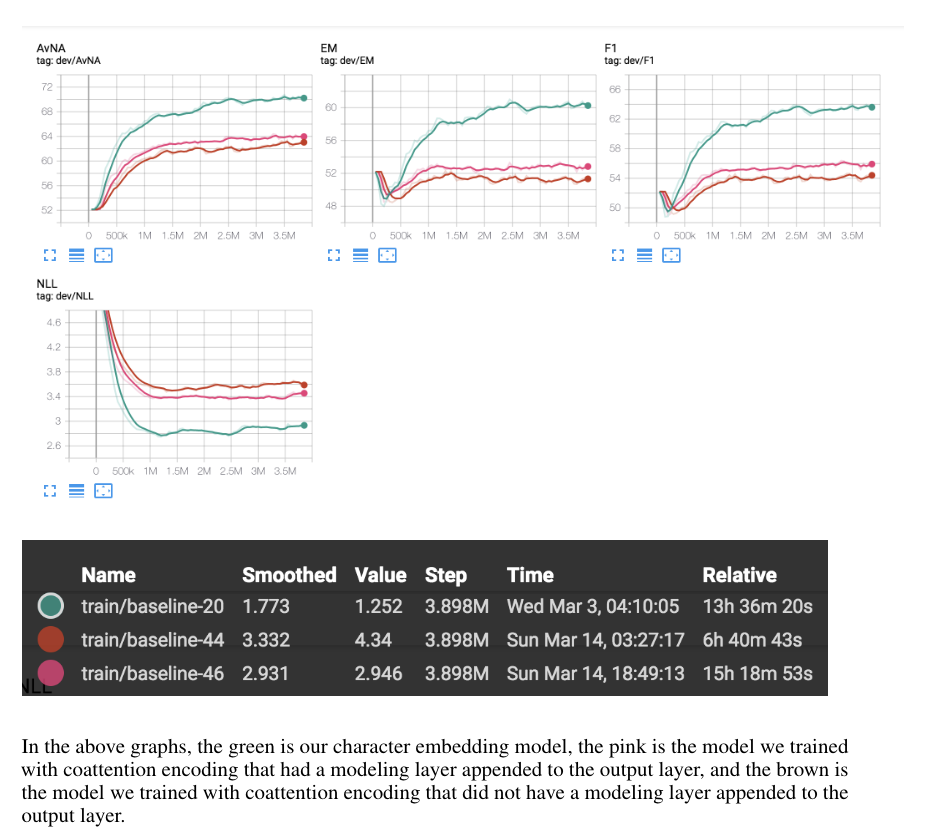
We explored a handful of different approaches on improving the SQuAD evaluation score within the context of coattention models. Immediately, we noticed character-level embeddings increase evaluation metrics by a few points and decided to explore coattention models with character-level embeddings. The performance of our coattention models without a dynamic decoder performed significantly worse than the baseline. We noted how removing the modeling layer reduced the training time in half while achieving a similar performance.
We hypothesized that the coattention model did not perform as well because the character-level embeddings introduced unnecessary and irrelevant similarities between the question and context embedding. Furthermore, we noted that there were some variance in the training runs especially in the F1 score. Some potential avenues for future work can explore removing character-level embeddings, reintroducing a dyamic decoder and observing the performance between a coattention model with and without a modeling layer to see if there are still improvements in training time. Furthermore, it would also be interesting to further explore the QANet model to understand how they intended to improve on training time.