Tackling SQuAD 2.0 Using Character Embeddings, Coattention and QANet
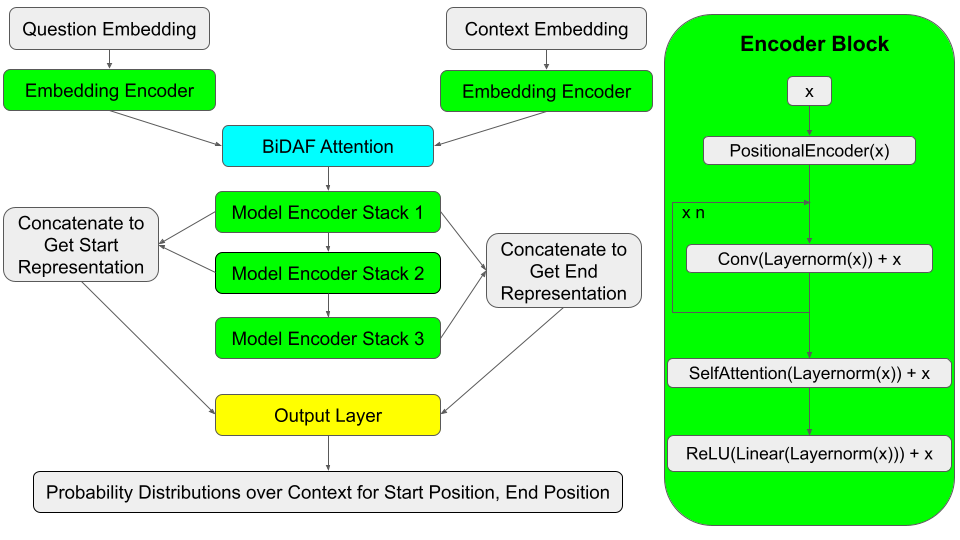
Question Answering (QA) systems allow users to retrieve information using natural language queries. In this project, we are training and testing QA models on SQuAD 2.0, a large dataset containing human-labelled question-answer pairings, with the goal of evaluating in-domain performance. Using a Bidirectional Attention Flow (BiDAF) model with word embeddings as a baseline, we identified, implemented and evaluated techniques to improve accuracy on the SQuAD task. Our initial experiments, which added character embeddings and a coattention layer to the baseline model, yielded mixed results. Therefore, we started over with a new model using Transformer-style encoder layers, based on the QANet. This model posed many challenges, particularly in adapting to the unanswerable component of the SQuAD 2.0 dataset, and thus did not come close to achieving the performance of BiDAF-based models.