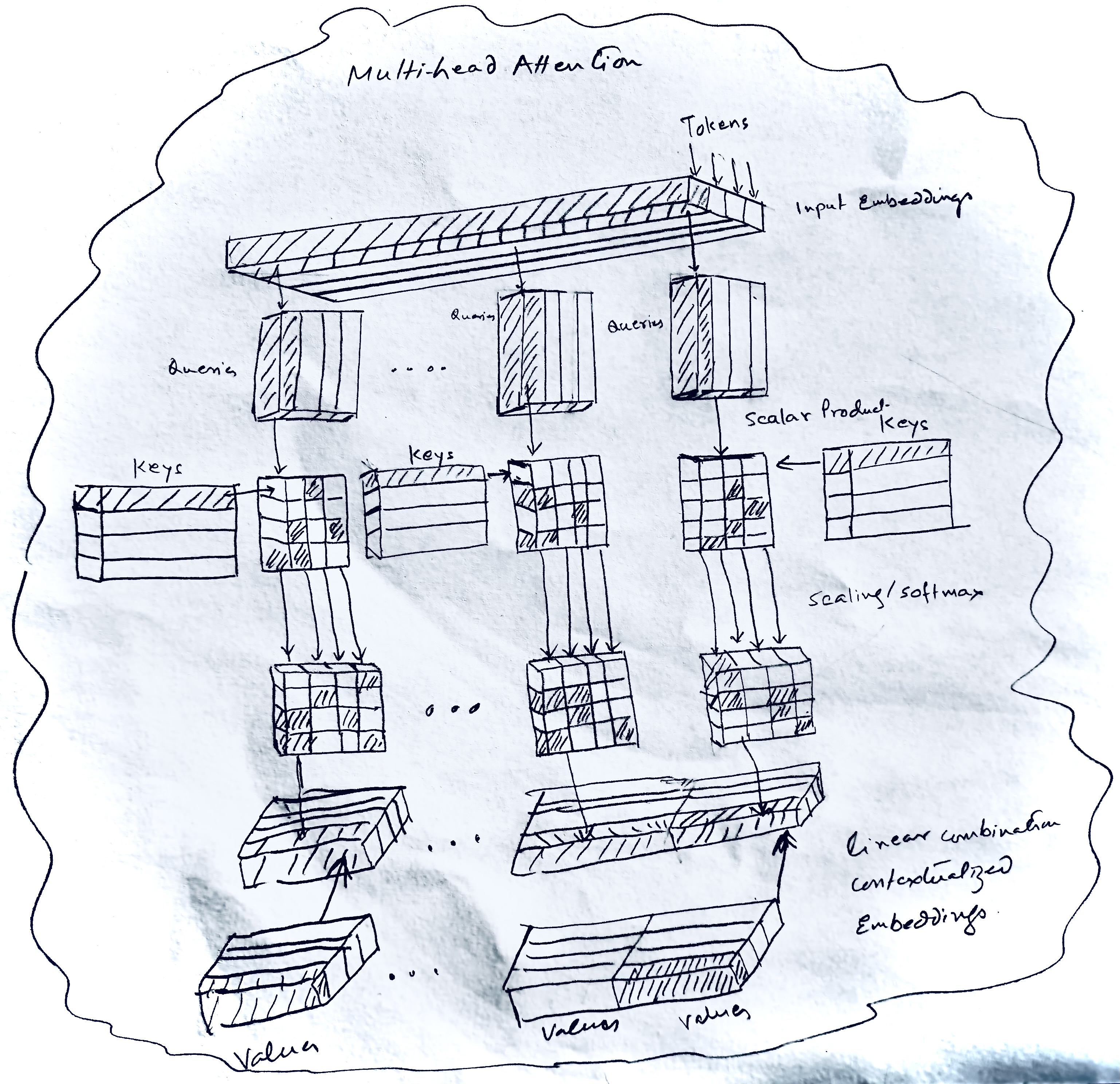
By exploiting self-matching attention in BiDAF and multihead attention in QANet, our project demonstrates that attention helps to cope with long term interactions in the neural architecture for question answering system. Our addition of self-matching attention in BiDAF matches the question-aware passage representation against itself. It dynamically collects evidence from the whole passage and encodes the evidence relevant to the current passage word. In QANet, convolution and self-attention are building blocks of encoders that separately encode the query and the context. Our implementation of multihead attention in QANet, ran through the attention mechanism several times in parallel. The independent attention outputs are then concatenated and linearly transformed into the expected dimension. Multiple attention heads allow for attending to parts of the sequence differently, so longer-term dependencies are also taken into account, not just shorter-term dependencies.
We saw some interesting trends while doing Qualitative error analysis of our output. Model was able to answer "who" questions better than "what" questions. When the "what" question was framed differently, like “Economy, Energy and Tourism is one of the what?” Even though the passage contains the answer, the model could not predict. Also, we observed wrong predictions in general for questions involving relationships, like: "Who was Kaidu's grandfather?" The passage did not mention it explicitly "Kaidu's grandfather was ...", however it had the clue: "Ogedei's grandson Kaidu ...", but it could not interpret the correct answer from the passage and instead provided a wrong answer. We also noticed the model could not predict at all a lot of "which" questions. Further analysis revealed that those "which" questions require a bit more contextual understanding. It was a good learning experience and the model prediction provided a lot of clues as to how we can improve the model to the next level.