Building a Robust QA System that Knows When it Doesn't Know
Machine Learning models have a hard time knowing when they shouldn't be confident
about their output. A robust QnA module should not only be able to do a good job at out of context data, but also be able to do a good job of knowing what data it can't handle. The goal of our project is to build a robust QnA model with an architecture that relies on a base of DistilBERT, improve on it through model fine-tuning, better optimization, and then augment the predictions of the model with a confidence score
Our approach for this project was forked in two directions.
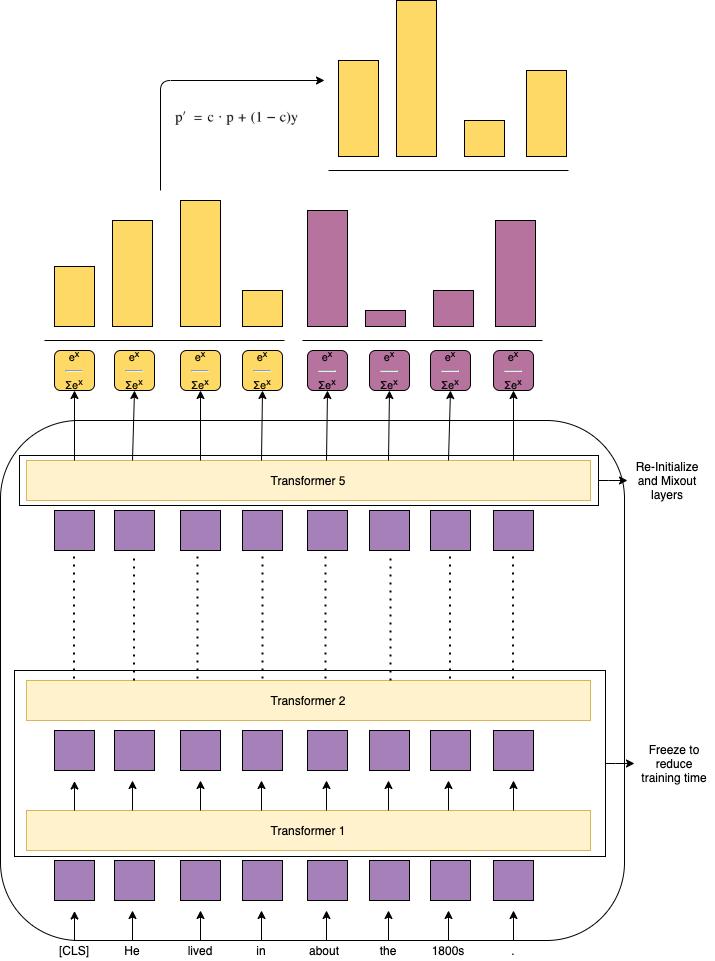
1. Focus on fine-tuning the model through approaches like transfer learning, longer epochs, mix-out and re-initializing layers.
2. Augment the model by providing a confidence score to enhance the model's reliability in real world usage.
BERT models use the base weights from pre-training and then fine-tune on specific datasets. They are pre-trained on a variety of tasks making it easier to generalize but it needs to be further fine-tuned for specific task. Also, the fine tuning process is susceptible to the distribution of data in the smaller datasets.
We aim to improve on this by training on larger epochs, freezing all but the last layers of the BERT model, re-initializing the pre-trained model weights, using a regularization technique called mixout, use the bias correction and finally add additional layers to the model.
The learnings from the experiments were:
1. Bias correction doesn't have any significant impact on the performance
2. Freezing the initial layers of DistilBERT doesn't impact the performance but it does speed up the training time
3. Re-initializing the lower layers have a positive impact on the performance of the model
4. Applying regularization in form of mixout increases the overall accuracy of the model