Improving Domain Generalization for Question Answering
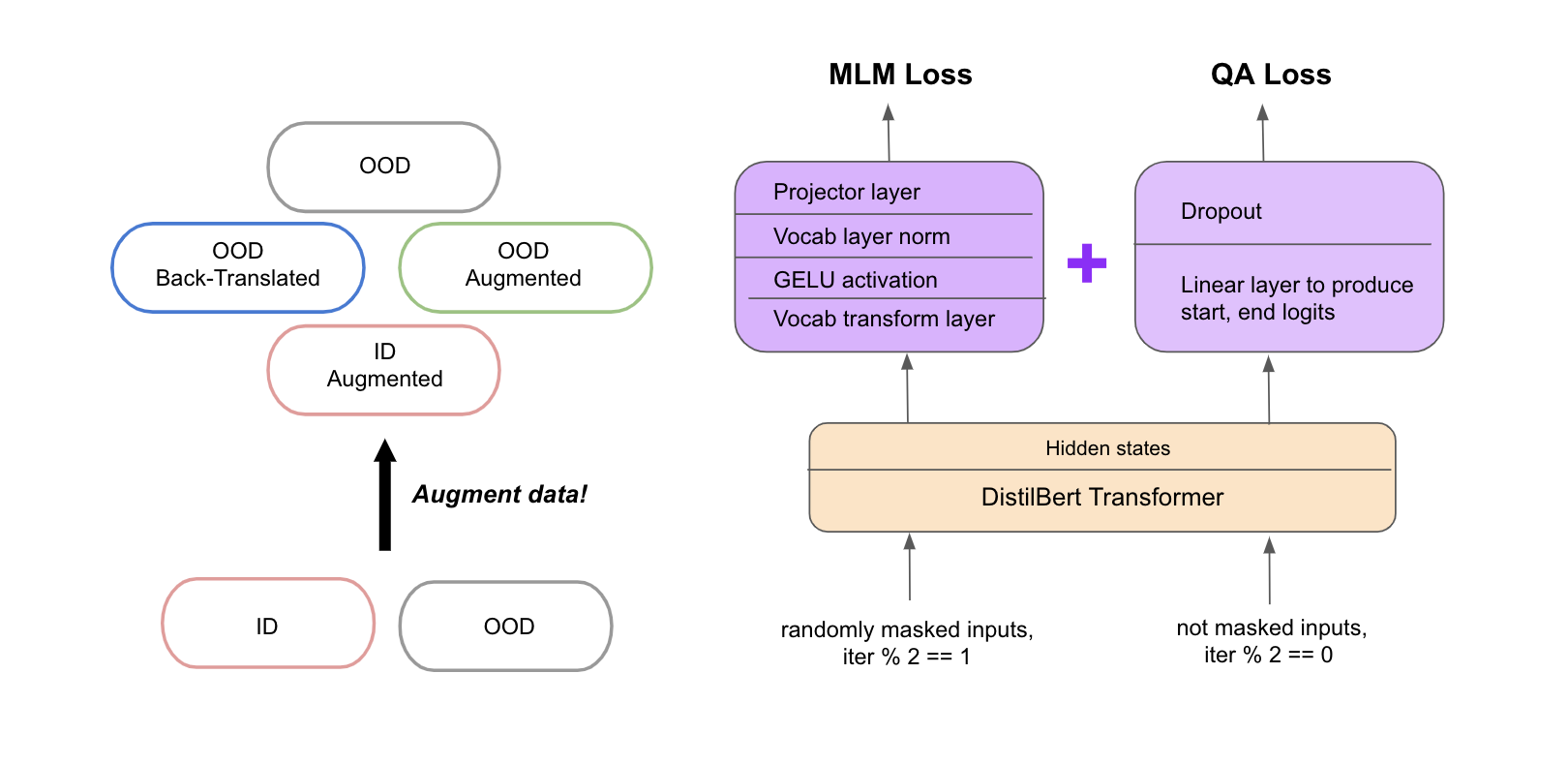
Domain generalization remains a major challenge for NLP systems. Our goal in this project is to build a question answering system that can adapt to new domains with very few training data from the target domain. We conduct experiments on three different techniques: 1) data augmentation, 2) task-adaptive pretraining (TAPT), and 3) multi-task finetuning to tackle the problem of producing a QA system that is robust to out-of-domain samples. We found that simply augmenting the in-domain (ID) and out-of-domain (OOD) training samples available to us, specifically using insertions, substitutions, swaps and back-translations, boosted our model performance with just the baseline model architecture significantly. Further pretraining using the masked LM objective on the few OOD training samples also proved to be helpful for improving generalization. We also explored various model architectures in the realm of multi-task learning and found that jointly optimizing the QA loss with MLM loss allowed the model to generalize on the OOD samples significantly, confirming existing literature surrounding multi-task learning. Hoping that these gains from data augmentation, adaptive pretraining, and multi-task learning would be additive, we tried combining the techniques but found that the sum of the techniques performed only slightly better and sometimes worse than the smaller underlying systems alone. Our best model implements data augmentation on both ID and OOD train datasets with the DistilBERT base model and achieved EM/F1 scores of 35.34/51.58 on the OOD dev set and 42.32/60.17 on the held-out test set. We infer that we've comfortably met our goal of beating the baseline model's performance as the baseline model achieved 32.98/48.14 on the OOD dev set.