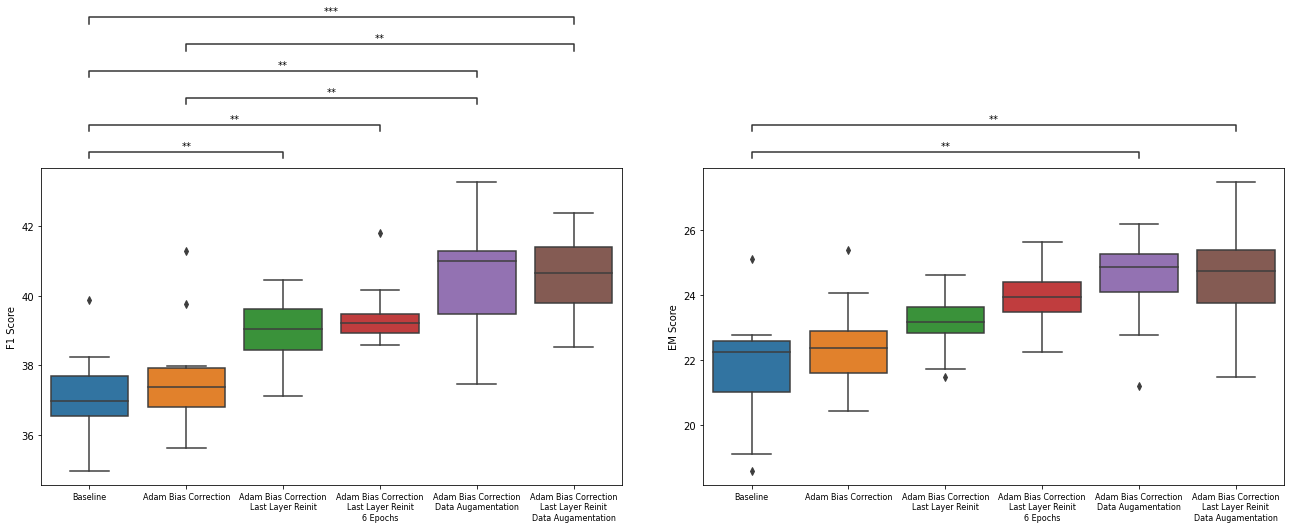
In this study we aim to modify three sub-optimal general practices of DistilBERT fine-tuning specifically for the question-answering language task, in order to improve both the predicting stability and performance of the model trained by the out-of-domain few samples datasets. We have implemented bias correction for the optimizer, re-initialization of the last transformer block and increase of the training iterations. With smaller sample datasets in the repeated experiment, the major finding is that the F1 score of the model performance has been improved by re-initialization but not by the other two implementations. It is also shown that the stability of finetuned model performance is improved by these implementations even though the improvements are not all statistically significant. In addition, we carry out an additional augmentation step of synonym substitutions for training datasets and show that both F1 and EM (Exact Match) scores are improved in the repeated experiments, with or without last layer re-initialization. Finally, we build a robust ensemble model based on six models that includes data augmentation with and without last layer re-initialization. Our model achieved performances of 43.096/62.205 (EM)/(F1) on out-of-domain test datasets.