Comparing Mixture of Experts and Domain Adversarial Training with Data Augmentation in Out-of-Domain Question Answering
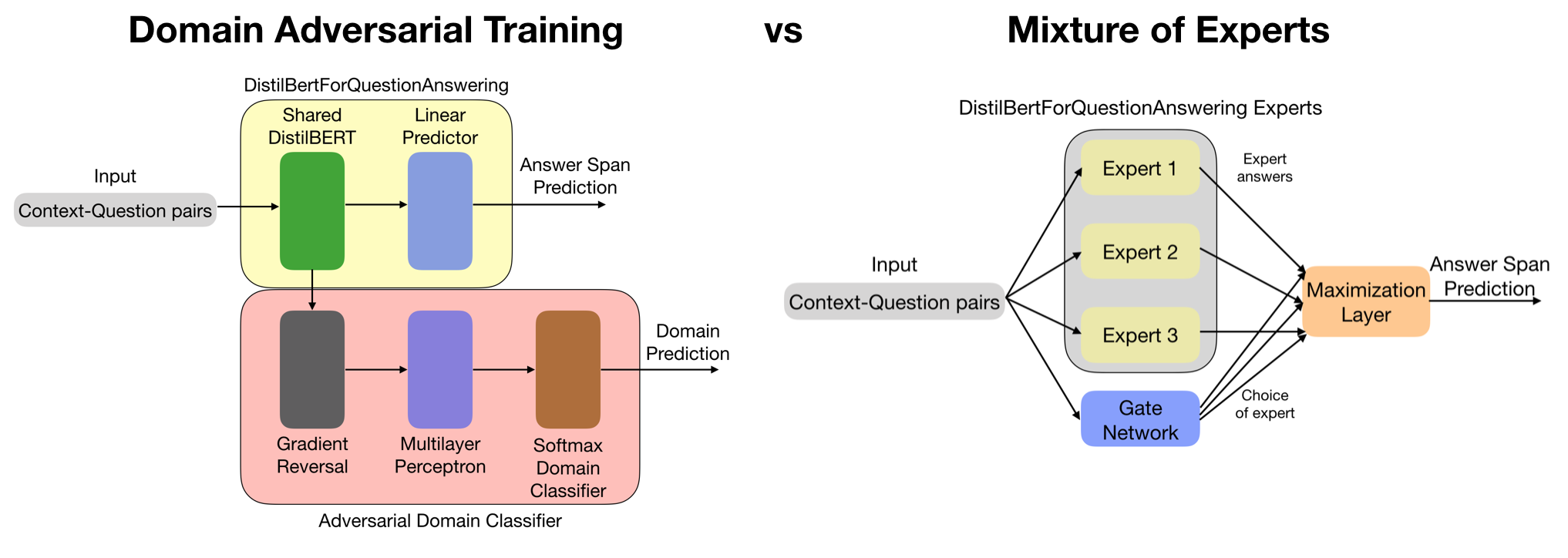
Generalization is a major challenge across machine learning; Question Answering in Natural Language Processing is no different. Models often fail on data domains in which they were not trained. In this project, we compare two promising, though opposite, solutions to this problem: ensembling specialized models (a Mixture of Experts approach) and penalizing specialization (Domain Adversarial Training). We also study the supplementary effects of data augmentation. Our work suggests that Domain Adversarial Training is a more effective method at generalization in our setup. We submit our results to the class leaderboard where we place 20th in EM.