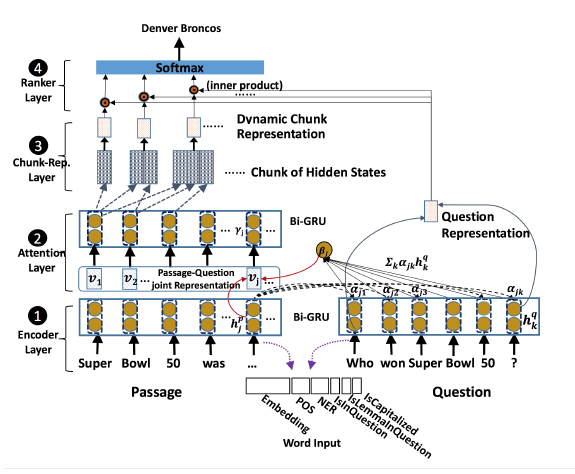
Some SQuAD models calculate the probability of a candidate answer by assuming that the probability distributions for the answer's start and end indices are independent. Since the two do depend on each other, it should be possible to improve performance by relaxing this assumption and instead calculating the probability of each candidate answer span's start and end indices jointly. We do so by reimplementing the Dynamic Chunk Reader (DCR) architecture proposed in Yu et al.\cite{yu2016end}, which dynamically chunks and ranks the passage into candidate answer spans using a novel Chunk Representation Layer and Chunk Ranker Layer. We implemented this model on the SQuAD 2.0 dataset instead of Yu et al.'s SQuAD 1 implementation. Our results performed more poorly than the baseline, which may indicate that the DCR architecture may not apply well to the SQuAD 2.0 task, or that we may have misinterpreted certain implementation details from the original paper.