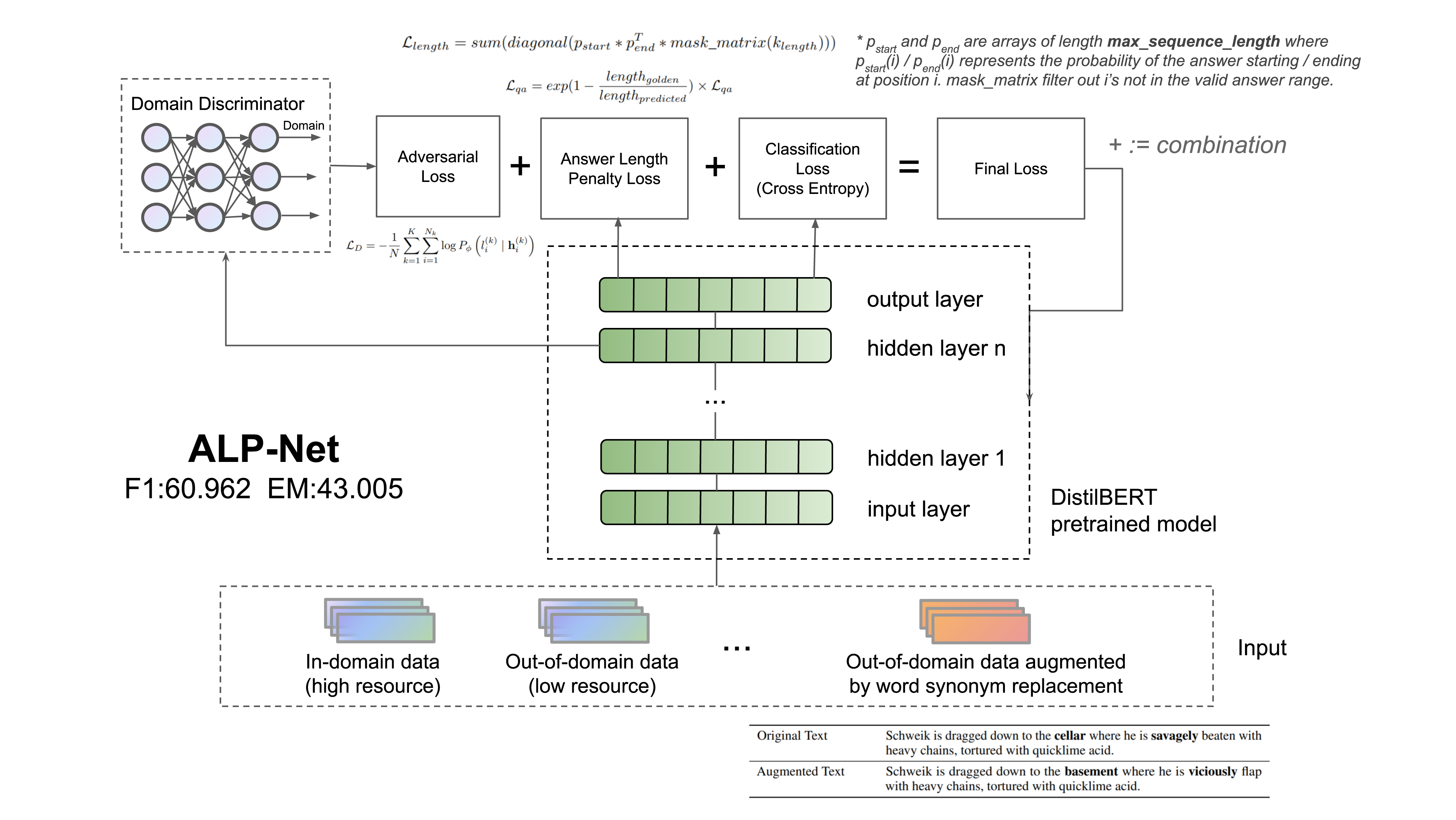
ALP-Net: Robust few-shot Question-Answering with Adversarial Training, Meta Learning, Data Augmentation and Answer Length Penalty
While deep learning has been very successful in the question answering tasks, it is very easy for models trained on a specific data to perform badly on other dataset. To overcome this, In our paper, we proposed ALP-Net to build a robust question answering system that can adapt to new tasks with few-shot learning using answer length penalty, data augmentation, adversarial training and meta learning.
1. First, We proposed a new answer length penalty that penalizes the model if the predicted answer is too long, as the baseline QA model tends to generate very long answers. This simple optimization is proved to be very effective in shortening the answers and improving Exact Match.
2. We also applied data augmentation to generate new data for low-resource datasets by doing synonym replacement and word addition. With data augmentation, the model is more unlikely to learn brittle features such as the occurrences of certain words and fixed answer positions, leading to improved F1.
3. ALP-Net also adopted adversarial training. We applied a discriminator to determine whether the features learned by the model are domain specific. With adversarial learning, models can learn domain agnostic features that could be applied to unseen domains. We found that while being effective in the few-shot learning task, adversarial training should not be used on out-of-domain training data to keep its domain knowledge.
4. We also tried meta learning to adopt the mean of different sets of model parameters learned from data of different domains. However, it did not perform well and we found that it is hard to learn general knowledge across domains for question answering tasks.
Among these approaches, data augmentation and answer length penalty contribute the most to our model performance, allowing us to achieve 60.962 F1 and 43.005 EM score on out-of-domain datasets test data.