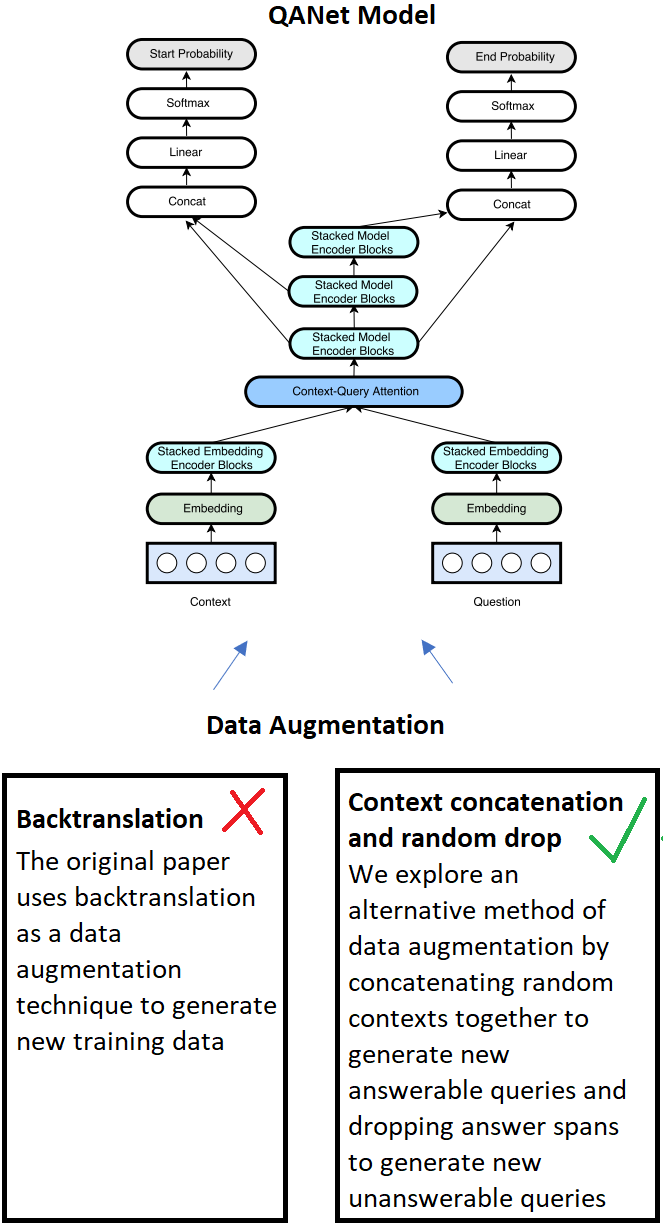
This paper investigates two different approaches to the question answering problem on the SQuAD 2.0 dataset. We explore a baseline model based on the BiDaF architecture, and improve its performance through the implementation of character embeddings and hyperparameter tuning. Further, we implement variations on the convolution and self-attention based QANet architecture. While the original QANet architecture uses backtranslation to do data augmentation, we explore a simple and effective method that does not have dependencies on machine translation systems to do augmentation. This involves concatenating contexts together and reusing the same query/answer to generate a new answerable query, and dropping an answer span from the context of an answerable query to create an unanswerable query. The effectiveness of this approach demonstrates the importance of data augmentation for the QANet model. Finally, we form an ensemble model based on our different experiments which achieves an F1 score of 70.340 and an EM score of 67.354 on the test set.