Experimenting with BiDAF Embeddings and Coattention
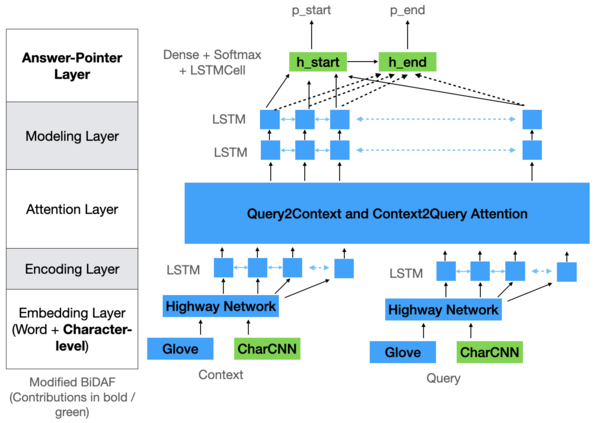
We are motivated by the task of question answering, which is a natural application of language models and helps evaluate how well systems understand the meaning within text. Our primary goal is to improve upon the baseline BiDAF model provided to us on the SQuAD 2.0 dataset, namely by experimenting with character-level embeddings, conditional end pointer predictions (Answer-Pointer network), self-attention, and coattention. We think that each of them leads in some way to an intuitive representation of language, linking it to larger aims within the field. Surprisingly, the coattention and self-attention modified models each score comparatively to or below the baseline model. Perhaps this hints at the importance of multiple layers for self-attention and word-to-word token interactions, as we only used one layer and a vectorized form of the original RNet self-attention paper. Our character-level embeddings + Answer-Pointer modified BiDAF performs best, scoring EM: 60.23 and F1: 63.56 on the dev set and EM: 58.715 and F1: 62.283 on the test set (compared to the baseline model with EM: 56.61 and F1: 60.24 on the dev set). The improvement might be attributed to a better understanding of out-of-vocabulary words and patterns in the grammatical structure of subsequence phrases. Compared to the baseline, the final model better predicts "No Answer"s and outputs semantically more logical context subsequences. However, the model still struggles with "why" questions and questions that contain different keywords than the context but have synonymous meaning (ex. "extremely short" in the context, "not long enough" in the question). Based on this error analysis, in the future we would love to explore euclidean distance between words and better beam search approaches to improve performance, as well as further analyze the failure cases of our self-attention / coattention implementations.