SQuAD 2.0: Improving Performance with Optimization and Feature Engineering
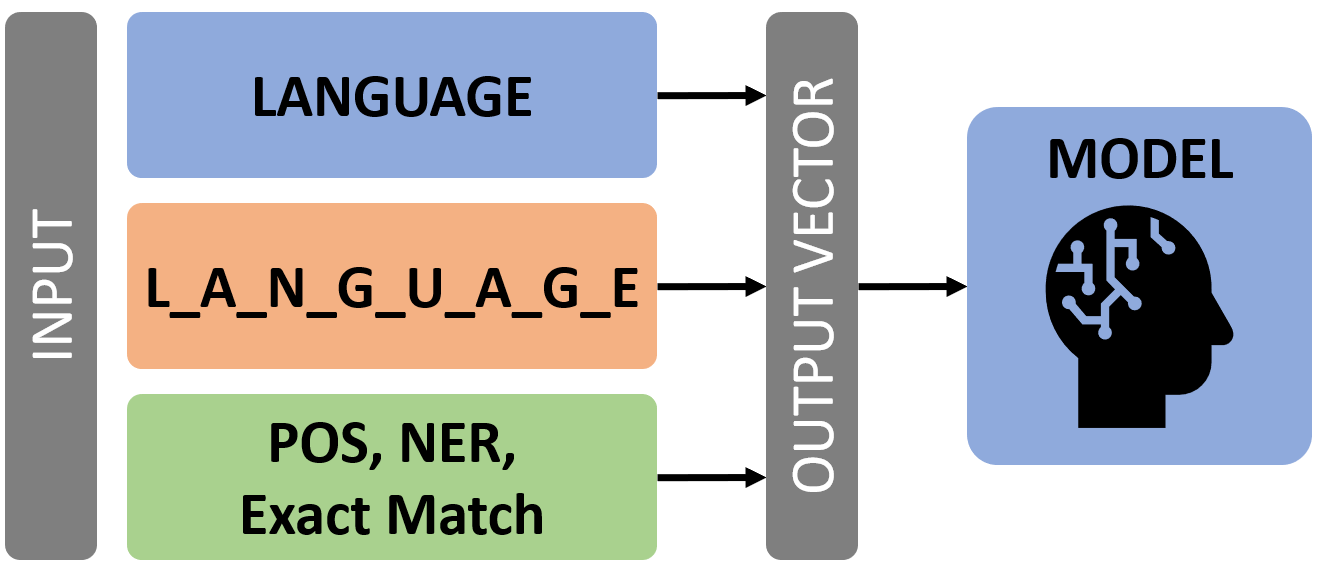
In this project, we significantly improved baseline performance on the SQuAD 2.0 question answering task through optimization and feature engineering. Instead of overhauling the original BiDAF network architecture, we focused on extracting as much information as possible from the input data, taking inspiration from the DrQA document reader. We first constructed character-level word embeddings via a 1D Convolutional Neural Network, and then added token and exact match features for both the context and question words. We also conducted thorough hyperparameter searches and experimented with various encoding methods, projection, and drop-out layers. Ensembling our best models by majority vote achieved validation set F1 and EM scores over 7 points higher than the baseline with comparable test set performance (F1=68.753, EM=65.714). Our findings suggest that feature engineering is a particularly effective approach to improve model performance in the absence of pretraining.