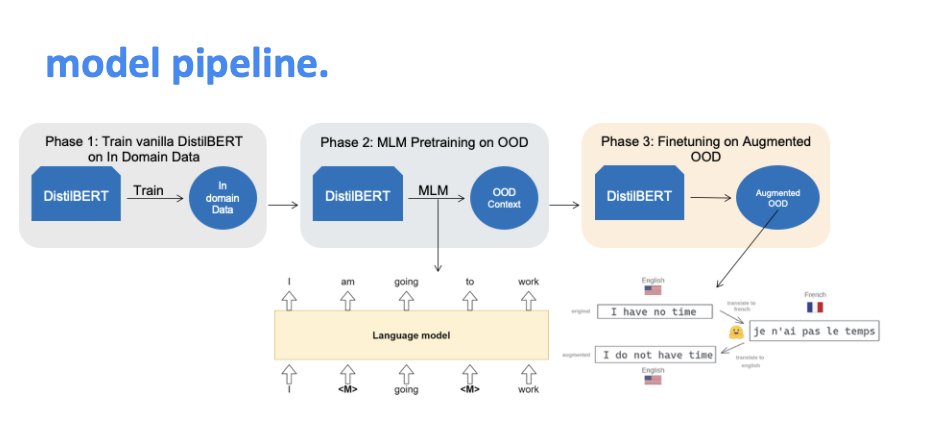
Researchers today prioritize their time by building increasingly complex models that are harder to interpret and debug. The goal of this project is for us to discover how noninvasive techniques can be equally as effective. We explore how accuracy improves with hyperparameter tuning, various different methods of learning rate decay, and layer freezing. We also analyze the effects of data-side augmentations such as backtranslation, synonyms, masked learning, and upsampling. The last area of exploration is an altered loss function that biases against length. Our main conclusions support that fine tuning and data augmentation methods were the most critical in improving performance on question answering systems under domain shifts. We see that data augmentation (back translation and synonym translation) however can sometimes be too noisy depending on how many sequences of languages we filter through, suggesting that future work looks into understanding an optimal number of languages. We have inconclusive results on the quality of MLM and upsampling our dataset as we see marginal improvement at best from these methods, potentially suggesting that they are not worthwhile pursuing for such few sample finetuning. Lastly, we see that for future work further investigation into our added loss function could be potentially useful in regularizing response length.