RobustQA: Benchmarking Techniques for Domain-Agnostic Question Answering System
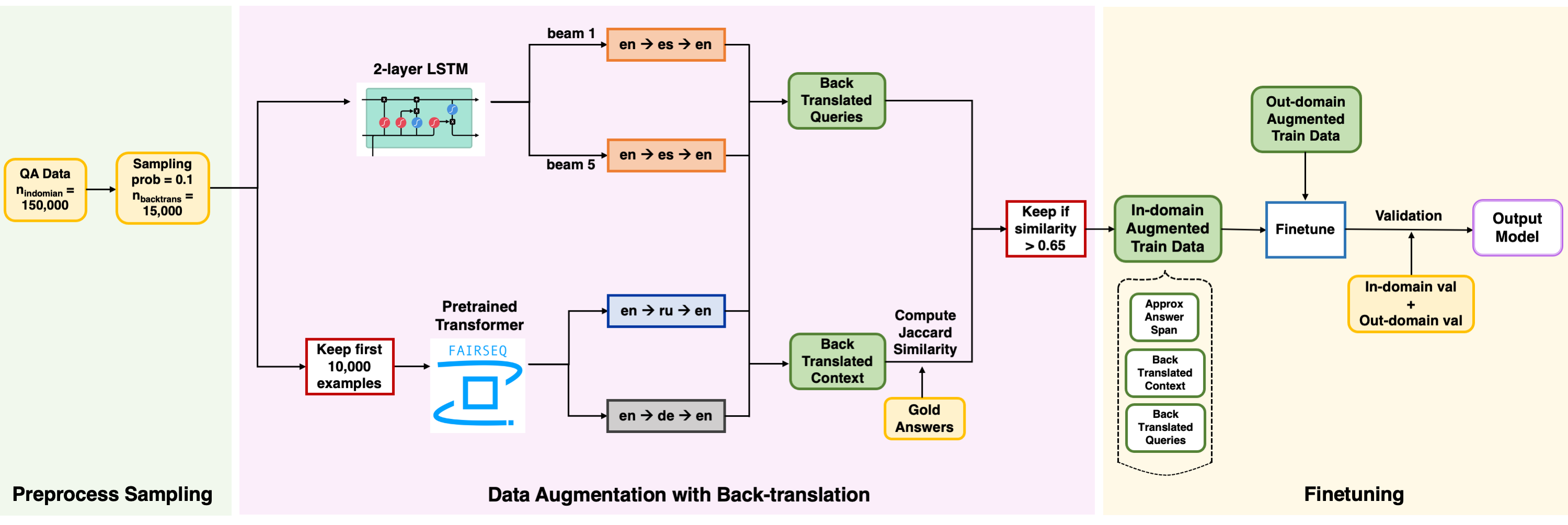
Despite all the hype about performances from large pretrained transformers like BERT and ROBERTA, it has been shown that Question Answering (QA) tasks still suffer challenges when there exists a large discrepancy between the training and testing corpus. The goal of our project is thus to build a question answering system that is robust to out-of-distribution datasets. We approach this challenge through data augmentation, where we hope to add label preserving invariances to the fine-tuning procedure to reduce the learned features specific to the in-domain data while increasing the number of the out-of-domain data that our QA model can generalize more broadly. Specifically, we paraphrased both the in-domain and out-of-distribution training sets by back-translating each query and context pair to multiple languages (Spanish, Russian, and German) using architectures that include a two-layer neural machine translation (NMT) system and pretrained language transformers. After back-translation, we iterate over all continuous subsets of words in the context sentence to find an approximate answer span that is the most similar to the original gold answer, and we filtered out examples with Generalized Jaccard similarity scores below 0.65 to ensure data quality. By fine-tuning the DistilBERT baseline on these augmented datasets, our best model achieved 51.28 F1 and 35.86 EM on the development set and 59.86 F1 and 41.42 EM on the test set.