Dataset Augmentation and Mixture-Of-Experts Working In Concert For Few-Shot Domain Adaptation Transfer Learning
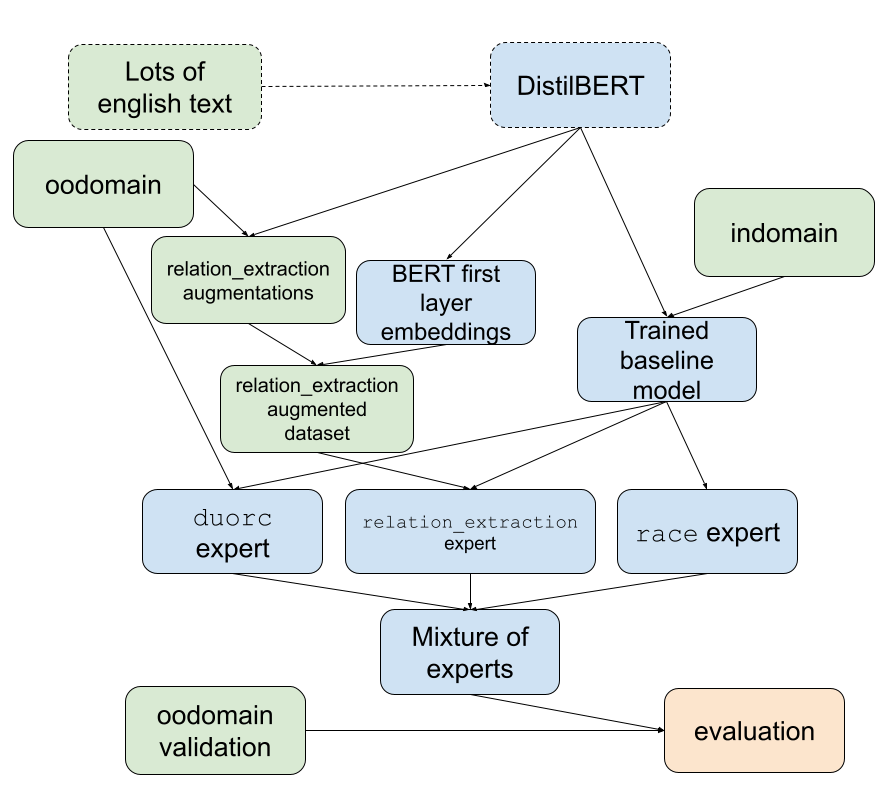
Despite the significant improvements in NLP in the last few years, models can still fail to work well on test sets which differ, even a small amount, from their training sets. Few shot learning is an important goal in creating generalizable neural network models. In this paper we explore ways to increase the few shot learning performance of a model by implementing a few variations meant to improve generalizability; specifically we measure the effects of data augmentation and mixture of experts on a pre-trained transformer BERT model. Mixture of experts is a technique in which separate models are trained to be responsible for different sub tasks within a problem. We find that this change is able to remove the interference between out-of-domain datasets during training and increase performance from F1 48.43 to 51.54. Data augmentation applied for NLP is a technique in which words within a piece of text are added, removed, or replaced in an effort to increase the variance in training data. This method was found to be a valuable tool in further improving expert learning, increasing the overall F1 score further to 52.07, however it did not improve the baseline model when used on its own.