BiDAF with Character and Subword Embeddings for SQuAD
In this paper, we have implemented subword embeddings and character-level embeddings on top of the word embeddings in the starter code.
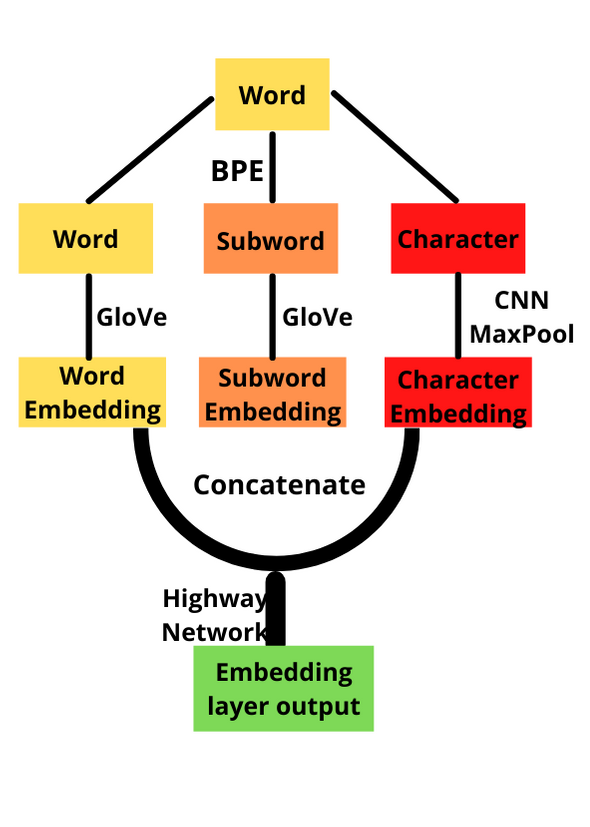
For the character embeddings, we followed the approaches outlined in the BiDAF paper[1]. The character's representation vectors were randomly initiated and then passed through a convolutional neural network. We then applied the ReLu function, as well as downsampling it using the maxpool function to get the representation vector for every word.
For the subword embeddings, we utilized the implementation of the Byte Pair Encoding algorithm[2]. It segments the word by grouping character sequences that occur most frequently in its training data. We then looked up the representation vector for each subword, which is trained using the GloVe algorithm(The segmentation and vector representation are both implemented in the Python library bpemb)[3]. We utilized the maxpool function to get the representation vector of each word, and then used linear transformation to convert the input features to match the hidden layers. Finally, we concatenated the three types of embeddings and passed them through the Highway Networks.
Among the different types of models we have experimented with, the model with the concatenation of word embeddings and character-level embeddings performs the best on the SQuAD v2.0 dev set: EM=61.39, F1=65.05.
References
[1]Minjoon Seo, Aniruddha Kembhavi, Ali Farhadi, and Hannaneh Hajishirzi. Bidirectionalattention flow for machine comprehension.arXiv preprint arXiv:1611.01603, 2016.
[2]Benjamin Heinzerling and Michael Strube. Bpemb: Tokenization-free pre-trained subwordembeddings in 275 languages.arXiv preprint arXiv:1710.02187, 2017.
[2]Jeffrey Pennington, Richard Socher, and Christopher D Manning. Glove: Global vectors forword representation. InProceedings of the 2014 conference on empirical methods in naturallanguage processing (EMNLP), pages 1532-1543, 2014.