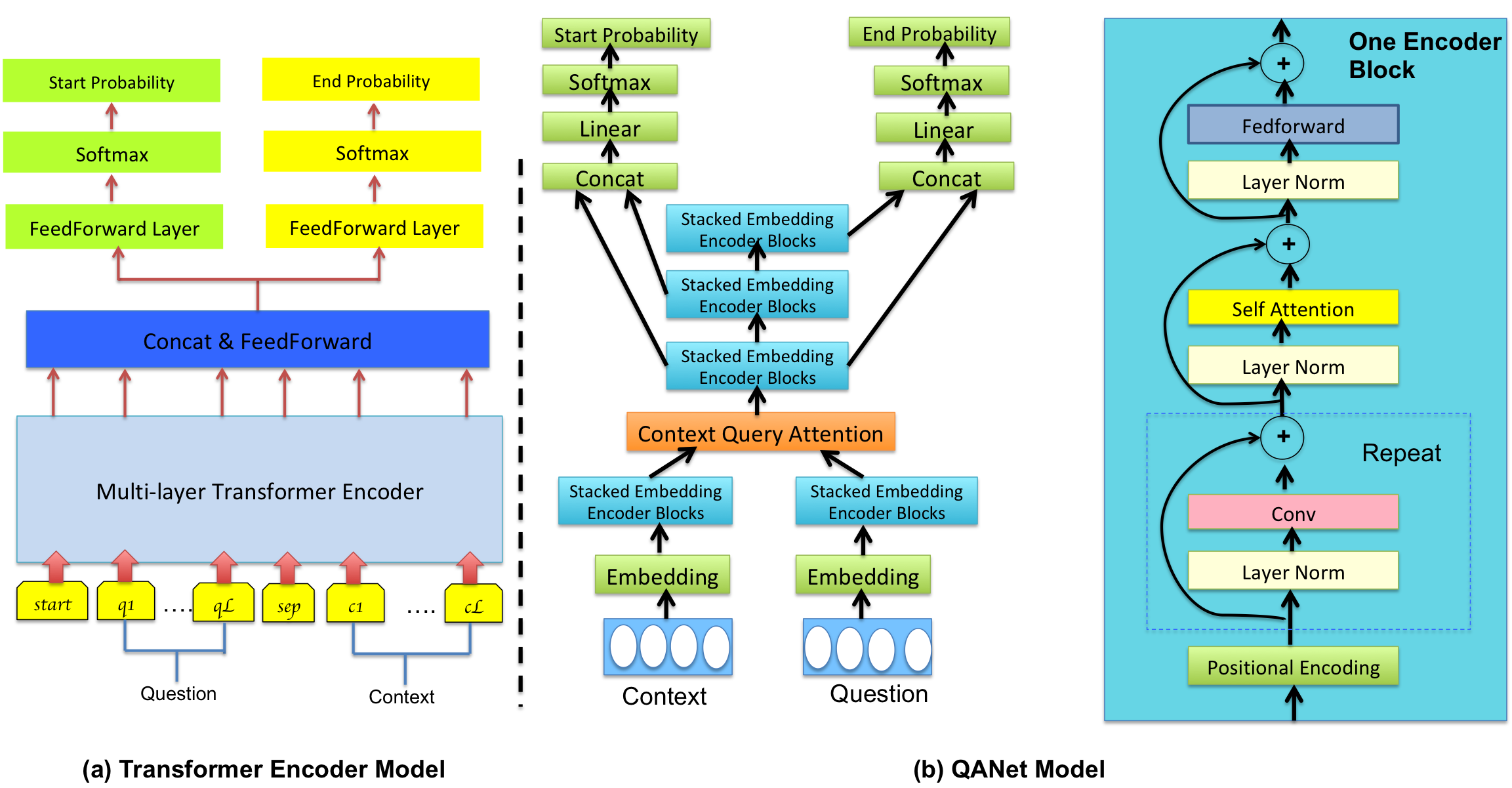
I implemented three NLP models : (a) a 4-layer 6 attention heads transformer encoder model, (b) QANet model and (c) extending the baseline BiDAF model with character embeddings for the question-answering task on the SQuAD dataset. The transformer encoder model (Fig (a)) is fed the sequence: "" where and are two special tokens indicating the start of the question and start of context respectively. To allow the model to predict no-answer, the context is prepended with a special (out-of-vocabulary) token. The output of the 4-layer transformer encoder is fed to a feedforward layer which is again fed to two different feedforward layers each followed by softmax, to predict the start and end position of answer in the context. The QANet Model (Fig (b)) replaces the LSTM encoder in BiDAF with self-attention and depthwise separable convolution. The model uses an encoder block (on right in Fig (b)) which contains multiple depthwise separable convolution layers followed by self attention and feedforward layer. The embedding layer (with character embeddings) and Context-Query attention are same as in BiDAF. The output of Context-query attention is fed to a stack of three encoder blocks, where the output of first two and first & third are used to predict start and end position of answer respectively through a projection layer followed by softmax. The transformer encoder model achieves EM and F1 score of 52.19 and 52.19 respectively while for the QANet model the scores are 57.28 and 60.59 respectively on the dev set. The QANet model was trained for 28 epochs and I believe that training it for longer (like 40 epochs) is likely to improve its performance. Adding character embedding to the baseline BiDAF model improves the EM and F1 scores from 55 and 58 to 59.6 and 63.14 respectively on dev set.