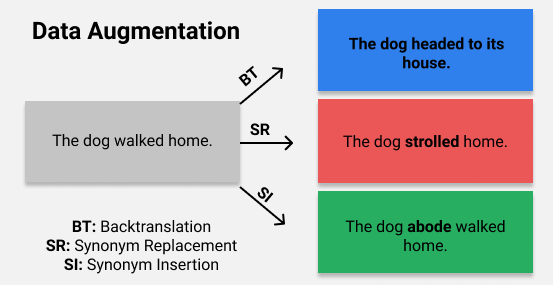
While question and answering (QA) models have achieved tremendous results on in-domain queries, recent research has brought into question the ability of these Q&A models to generalize well to unseen data in other domains. To address this, we aim to build a robust question answering system, which trained on a set of in-domain data can then be adapted to unseen domains given few training samples. Our main approach is the field of data augmentation. In this work, we conduct a survey of existing data augmentation methods, including backtranslation, synonym replacement, and synonym insertion, as well as introduce a mixed data augmentation method (MDA) combining the previous three. For examples of backtranslation, synonym replacement, and synonym insertion, please see the displayed figure. The figure displays three examples for how one sentence might be augmented using each data method. In particular, we explore the efficacy of data augmentation in the task of question answering. We find that data augmentation provides moderate gains on our out of domain validation and test sets and that certain methods such as backtranslation and synonym replacement provide larger improvements compared to others. Overall, we confirm that data augmentation is a simple, generalizable technique with a wide variety of different methods that can effectively aid in improving the robustness of Q&A models in the face of unseen domains with few training examples.